0%
iOS image 内存优化
iOS Image 内存优化
结论
在iOS 原生层,对于图片的使用,推荐使用 UIGraphicsImageRenderer API
也需要合理在不同的使用场景,根据场景需要类型使用正确的API ,同时对图片资源做加载和释放管理。
前因
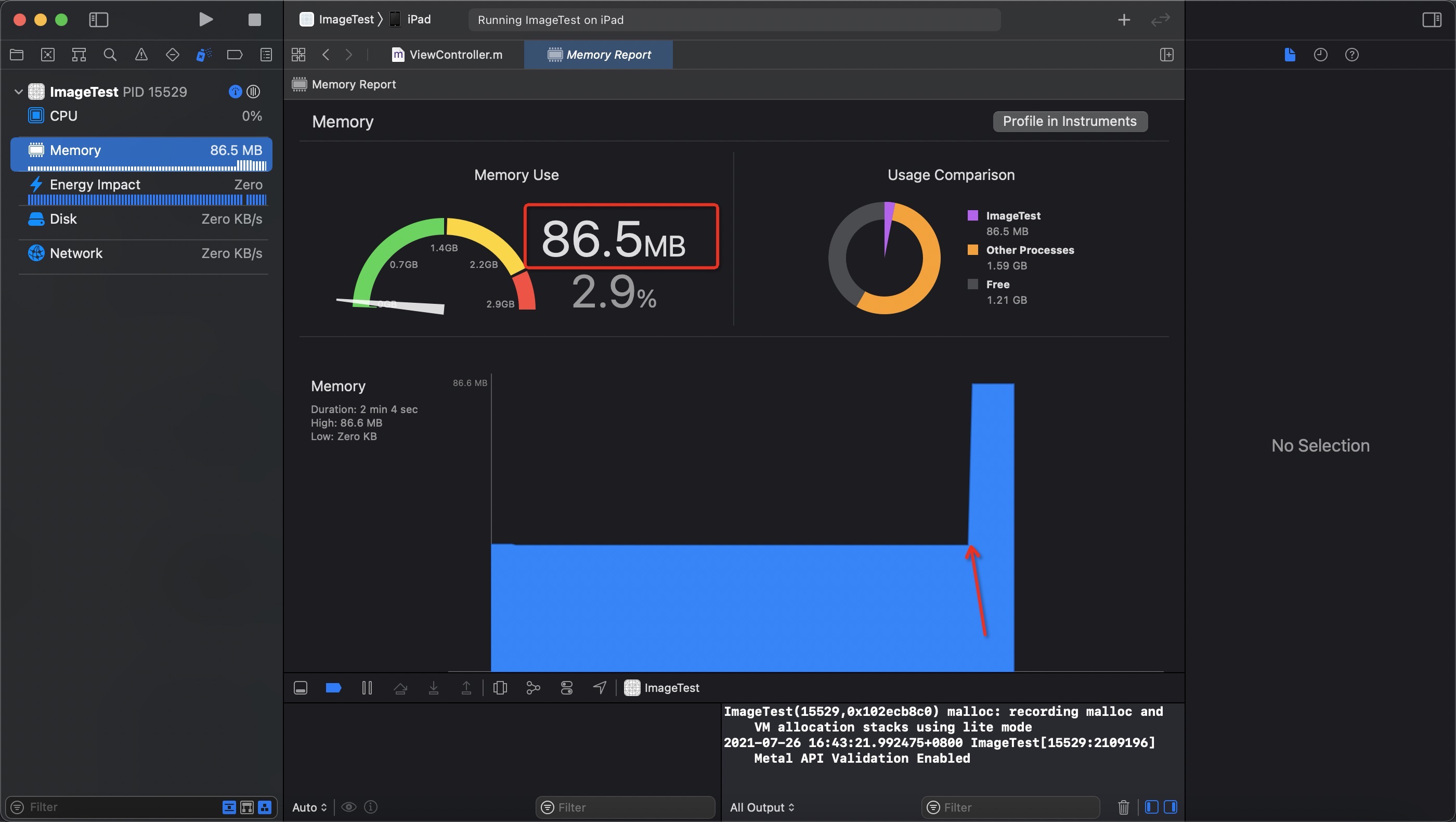
看看上面的这个图,有没有考虑过,iOS 里面一张 4096 * 3072 尺寸的png图片占用多大内存呢 ?答案是惊人的 48M
计算公式是这样的 image width * image height * 4 /1024 / 1024 这里认为 image 属于RGBA8888
问题来了,内存都在哪里 ?
深究一下iOS 内存分配逻辑可以有下面的结论,iOS 内存部分分为三类,即:Data Buffer、Image Buffer、Frame Buffer
Data Buffer 是存储在内存中的原始数据,图像可以使用不同的格式保存,如 jpg、png。是Image 的文件内容。
Image Buffer 是图像在内存中的存在方式,用于存放图像具体素点信息。Image Buffer 的大小和图像的大小成正比。
Frame Buffer 和 Image Buffer 内容相同,不过其存储在 vRAM(video RAM)中,而 Image Buffer 存储在 RAM 中。
解码就是从 Data Buffer 生成 Image Buffer 的过程。Image Buffer 会占用带宽上传到 GPU 成为 Frame Buffer,最后GPU负责使用 Frame Buffer用于更新显示区域。

大致执行流程如上图,先经过载入,加载图像内容到内存成为Data Buffer , 然后就是经过Decode 过程,转化图像为GPU 可用的 Image Buffer ,在需要显示的时候Image Buffer data 会被上传到GPU 中成为Frame Buffer Data 进行相应渲染。
上图飙升的 48M 内存代码如下
1 | //原图加载 |
UIImage 是 iOS 中处理图像的高级类。创建一个 UIImage 实例只会加载 Data Buffer,将图像显示到屏幕上才会触发解码,也就是 Data Buffer 解码为 Image Buffer。Image Buffer 也关联在 UIImage 上。
imageNamed 这个常用API 存在一个内存问题,就是载入以后图片会被缓存到系统Cache 里面。 这是一种便捷的设计,比如可以快速在cache 里面查找到图片的缓存,同时也是一个弊端,内存就放在了cache 里面,一部分内存就会被持续占用。如果是比较小,又常用的图片,这么处理比较合适,但是针对于例子中的尺寸来讲,就非常不合适。
对于这个问题,大家通用的解决方案应该是 使用 imageWithContentsOfFile这个 API 来搞,根据苹果的解释是:使用这个方法创建的图片不会缓存于系统缓存内,开发者可在适当的时机对图片进行处理。因而,对于一些比较大的或不常使用的图片,我们应当使用imageWithContentsOfFile:进行创建。
1 | -(void)withContexOfFile{ |
API 的本身用途是不在cache 里面缓存图片内容,但是图片占用的内存依然很大。
优点 : 图片不使用即释放内存,不存在图片常驻内存
缺点 : 每次使用都需要做IO的操作
适用于使用不频繁的大图加载
有没有更好的方式来降低图片内存 ?
答案,有! 参考 Image and Graphics Best Practices WWDC2018
所以引出这里的重点: UIGraphicsImageRenderer
代码先:
1 | -(void)resizeTest |
先给出一组数据对比 图片尺寸同样缩放在 1367 / 2 , 1089 / 2
图1 使用 imageNamed API , 发现 Physical footprint 明显增加了 48M, 内存块儿在 IOSurface
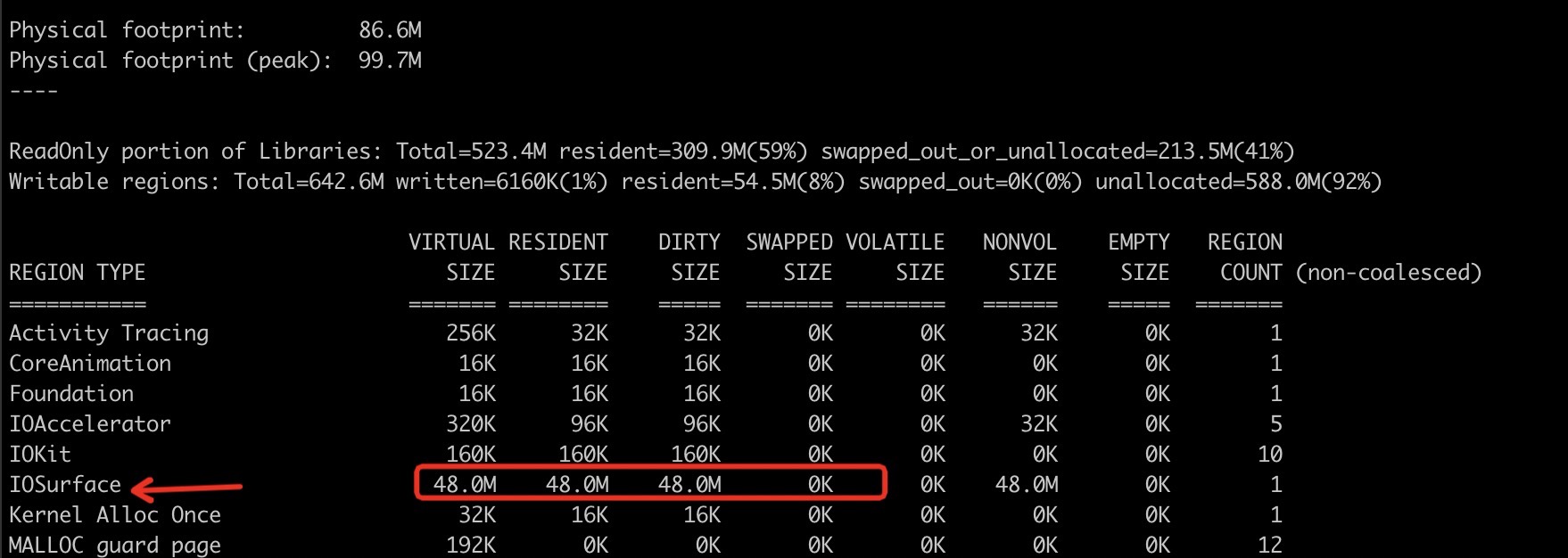
IOSurface 内存块儿增加是因为 图片decode 之后生成的位图,内存会被分类到这里
图2 使用 UIGraphicsImageRenderer API
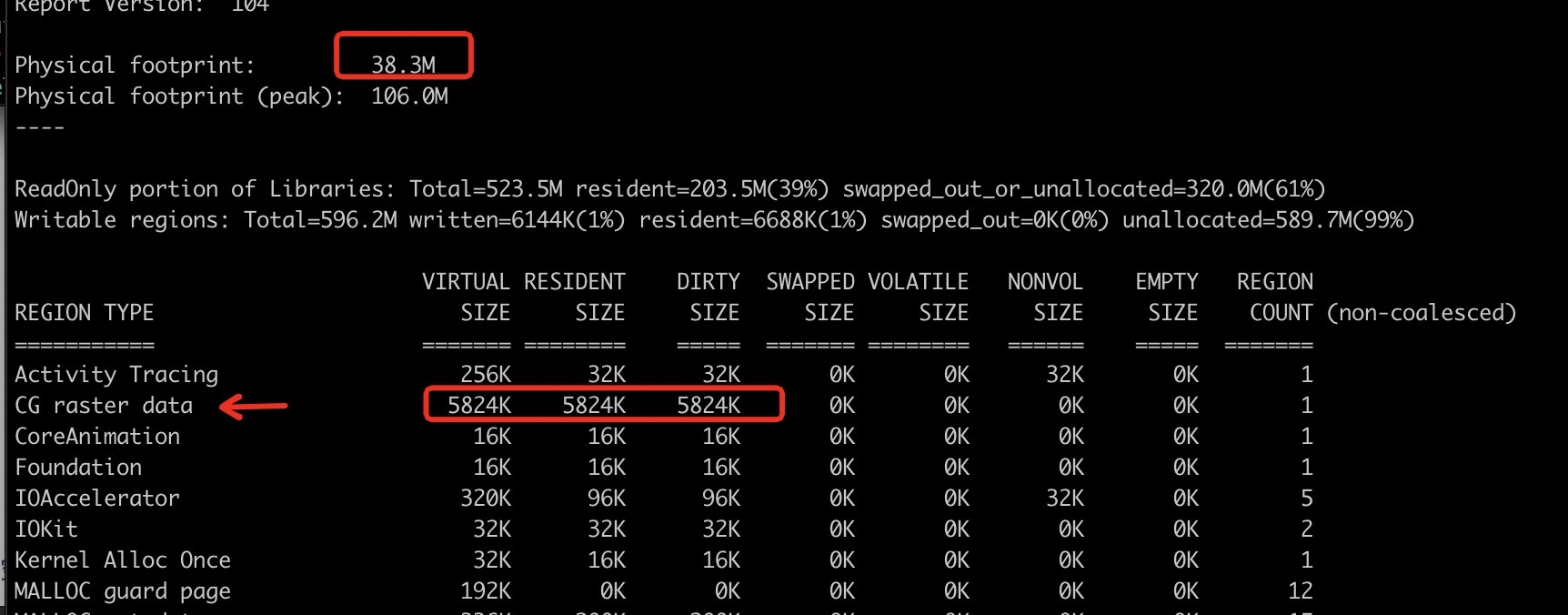
明显观察到的内容是 占用巨大的 IOSurface 不存在了,但是内存块儿多了一个 CG raster data 大小为 5824K
1367 * 1089 * 4 / 1024 = 5815.08984375 跟 5824 很接近是不是 ? 可是又会有一点儿感觉不对,图片的宽和高都没有按照缩放的size 进行计算。于是就这个问题又去查了一下。
UIGraphicsImageRenderer 实现的原理是,系统可以根据图片分辨率选择创建解码图片的格式,如选用SRGB format 格式,每个像素占用 4 字节,而Alpha 8 format,每像素只占用 1 字节,因此可以减少大量的解码内存占用。
使用 UIGraphicsImageRenderer 之后这张图片physical footprint增加了多少内存 ? 0.2M
那么优化了多少内存呢 (48 - 0.2) / 48 = 0.996 , 释放了 96% 的可用空间。
C++ 跨平台业务实例
C++ 跨平台业务相关实例
前因
我们业务方有多端:iOS 、Android 、win、Mac 。于是需要使用跨平台统一的相关业务功能。
现状是存在多端的开发人员,多个技术栈,如果加上管理和沟通不畅,一个需求会有多个版本。以最好的状态来估计,出现不同的逻辑但是业务都正常是有可能的。但是只要有人员介入参与项目开发,出现问题是必然的。如何查找和后期稳定维护将是一个巨大的灾难。
那么如果使用C++来作为基础业务开发,好处是显而易见的,即直接编译成为二进制,速度优势明显。但是缺陷是,如果开发人员出现了很小的失误,带来的问题是巨大的,毕竟太多的用户不太愿意升级App
回归正题
正常来讲,C++ 在跨平台游戏引擎中比较常见。也因为业务需要分端开发的成本比较高,C++ 作为底层通用组件对于跨平台应用来讲是一个不错的选择。根据这一点简单讲一下如何才能使用一套代码进行四端编译。
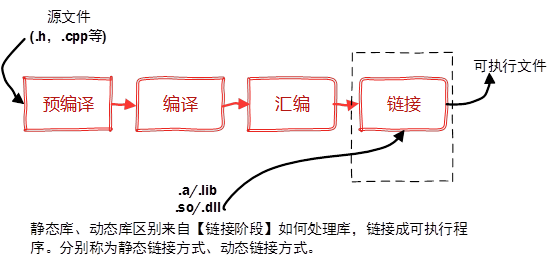
需要先科普一下静态库和动态库。
静态库
静态库即静态链接库(Windows 下的 .lib,Linux 和 Mac 下的 .a)。之所以叫做静态,是因为静态库在编译的时候会被直接拷贝一份,复制到目标程序里,这段代码在目标程序里就不会再改变了。
静态库的好处很明显,编译完成之后,库文件实际上就没有作用了。目标程序没有外部依赖,直接就可以运行。当然其缺点也很明显,就是会使用目标程序的体积增大。
动态库
动态库即动态链接库(Windows 下的 .dll,Linux 下的 .so,Mac 下的 .dylib/.tbd)。与静态库相反,动态库在编译时并不会被拷贝到目标程序中,目标程序中只会存储指向动态库的引用。等到程序运行时,动态库才会被真正加载进来。
动态库的优点是,不需要拷贝到目标程序中,不会影响目标程序的体积,而且同一份库可以被多个程序使用(因为这个原因,动态库也被称作共享库)。
我们知道动态库有各种好处,比如包体比较小,可以被多个库使用等,但是由于iOS 在审核时候对于动态库是不持推荐态度,而且,需要依赖系统环境等。
我们有一个原生需求,就是使用C++ 版本的Websocket, 使用底层提供公共功能。
选型
在GitHub 上面,根据排名列了一下顺序。
websocketpp 4.8K star
boostorg/beast 3.1K star
warmcat/libwebsockets 3.1K star
以稳定和快速开发,采用了websocketpp 。 没有采用 libwebsocket 的另外一个原因是,在比较少的示例代码中,查找异常出现的错误码都是一件极为难的事情。
websocketpp 这个库没什么特别大的问题,唯一的问题是需要依赖boost 库,生成二进制比较大。
问题呢都不是很大,吭哧吭哧的搞好几天,boost 相关依赖环境和相关编译环境就配置好了,下一步就是如何生成相应的静态库。
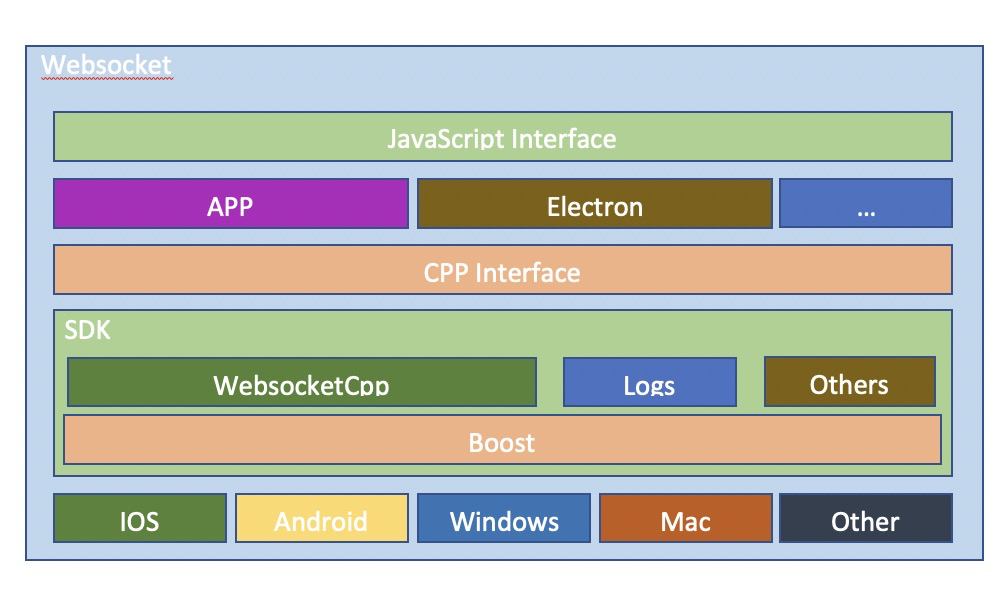
项目比较特殊,遗留问题,游戏引擎部分选择了不开源的Laya . 又因为业务侧,laya 自己封装的libWebsocket 在遇到相关网络问题的时候力不重新,所以才会有使C++ 版本Websocket 来替换掉 Laya 提供的Websocket 的需求。
结构如需求,很简单,通过基础boost 提供基础相关能力,在上层去扩充子插件。通过插件提供的基础能力,封装相应接口暴露给上层去使用。
因为本身项目的问题,
Appium 自动化测试验证步骤
Appium 自动化测试验证步骤
目的:
为了自动化测试APP,想要高效验证内容
已知:
可用有,PrefDog ,Appium, 且PrefDog 已经有完善的相关自动化脚本
存在问题:
自动化在于教师端,需要操作教师端,客户端用于性能验证,单一的监听
我们要求肯定不能满足于这样,我需要客户端自动操作,用于验证内容。
结论
Appium 对于iOS 自动化测试很好用,但是对于我们的Hybrid类型App 似乎不是特别好用。
折腾步骤
新电脑,安装环境啥的,因为网上有太多的安装教程,这里不想多说。Appium Mac 安装教程
给设备安装
WebDriverAgent推荐去Appium 的安装包下面去运行, 具体的方法参考
1 | cd /Applications/Appium.app/Contents/Resources/app/node_modules/appium/node_modules/appium-WebDriverAgent |
- 打开Appium 客户端,配置如下
1 | { |
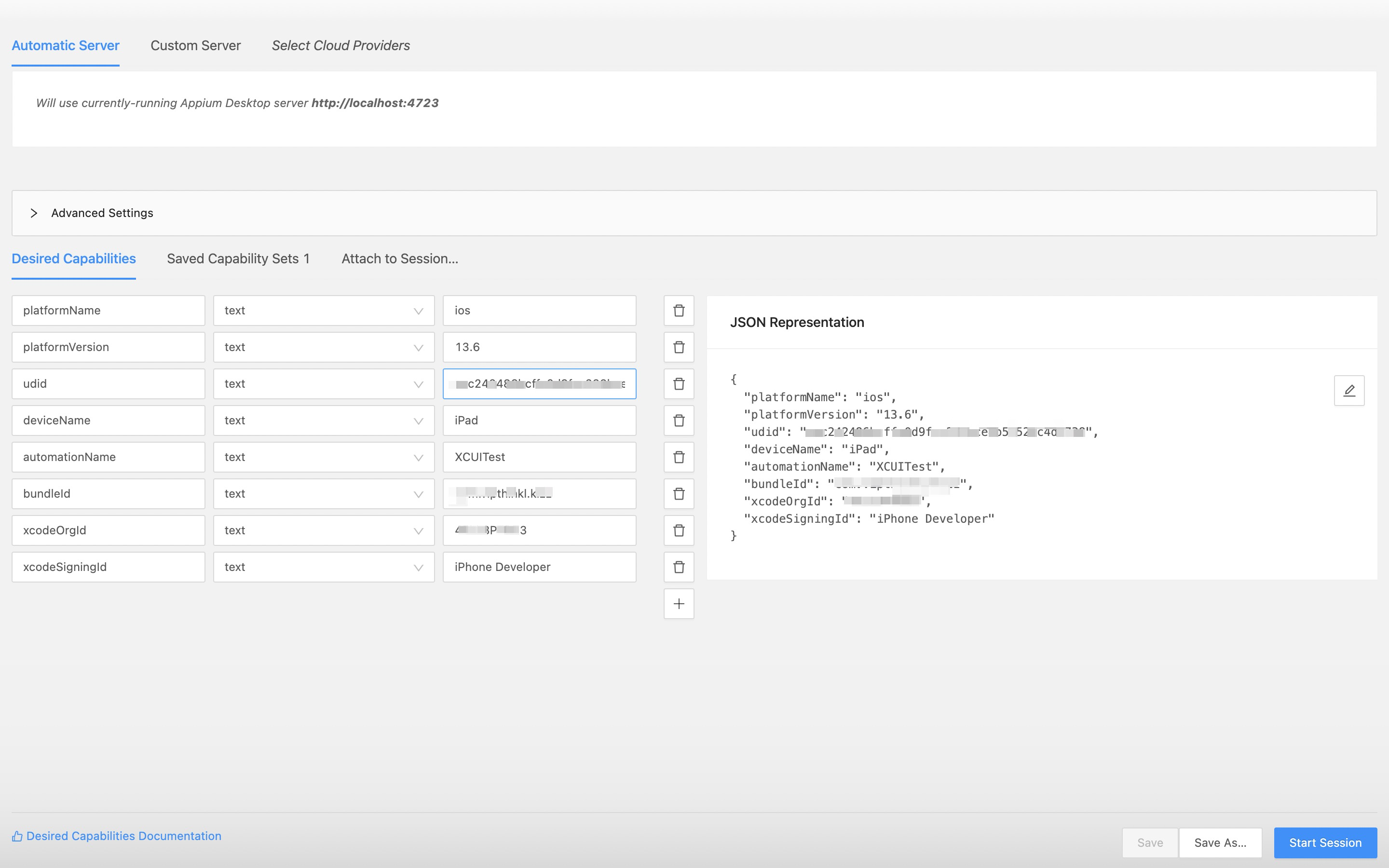
点击
Start Session前提 Xcode 在运行当前 WebDriverAgent ,然后 Appium 会自动拉起设备上指定的bundleId App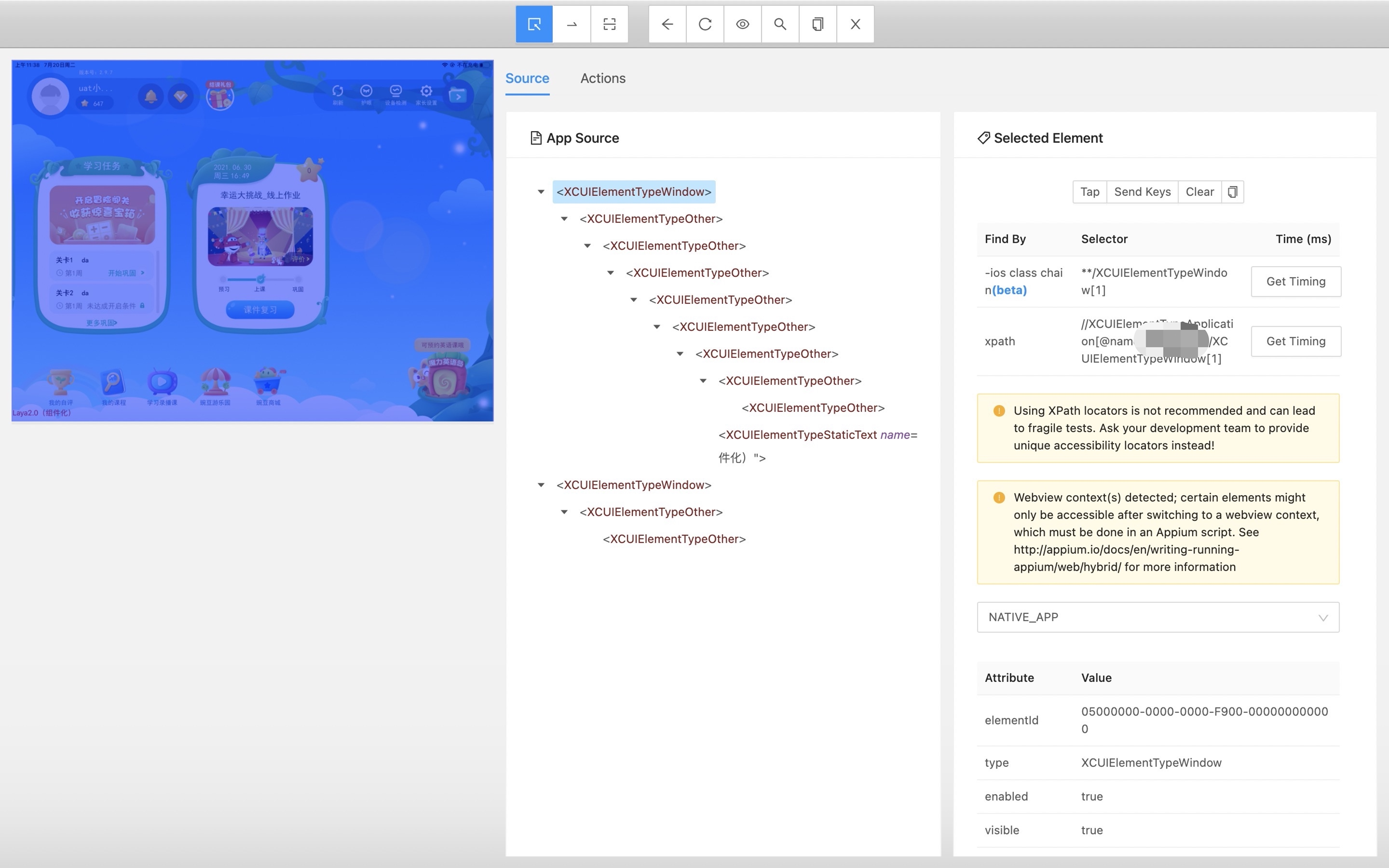
问题来了,发现App Source 里面没有我们想要的button 之类的,因为没有特殊id 就没办法进行相应自动化。我们的项目是给予Laya Native 的App , 显示区域是JavaScript 调用GLKView进行绘制,所以,抓不到iOS UI 控件应该是正常的。
有没有其他方式
在准备宣布说无法调试Laya JavaScript 的时候,我看到了这个 appium 使用ios_webkit_debug_proxy。
感觉我又有了希望,安装步骤依然忽略,安装以后配置appium
1 | { |
能够完美拉起 Safari , 也能看到Safari 里面的标签内容,但是不是我们想要的App 内容
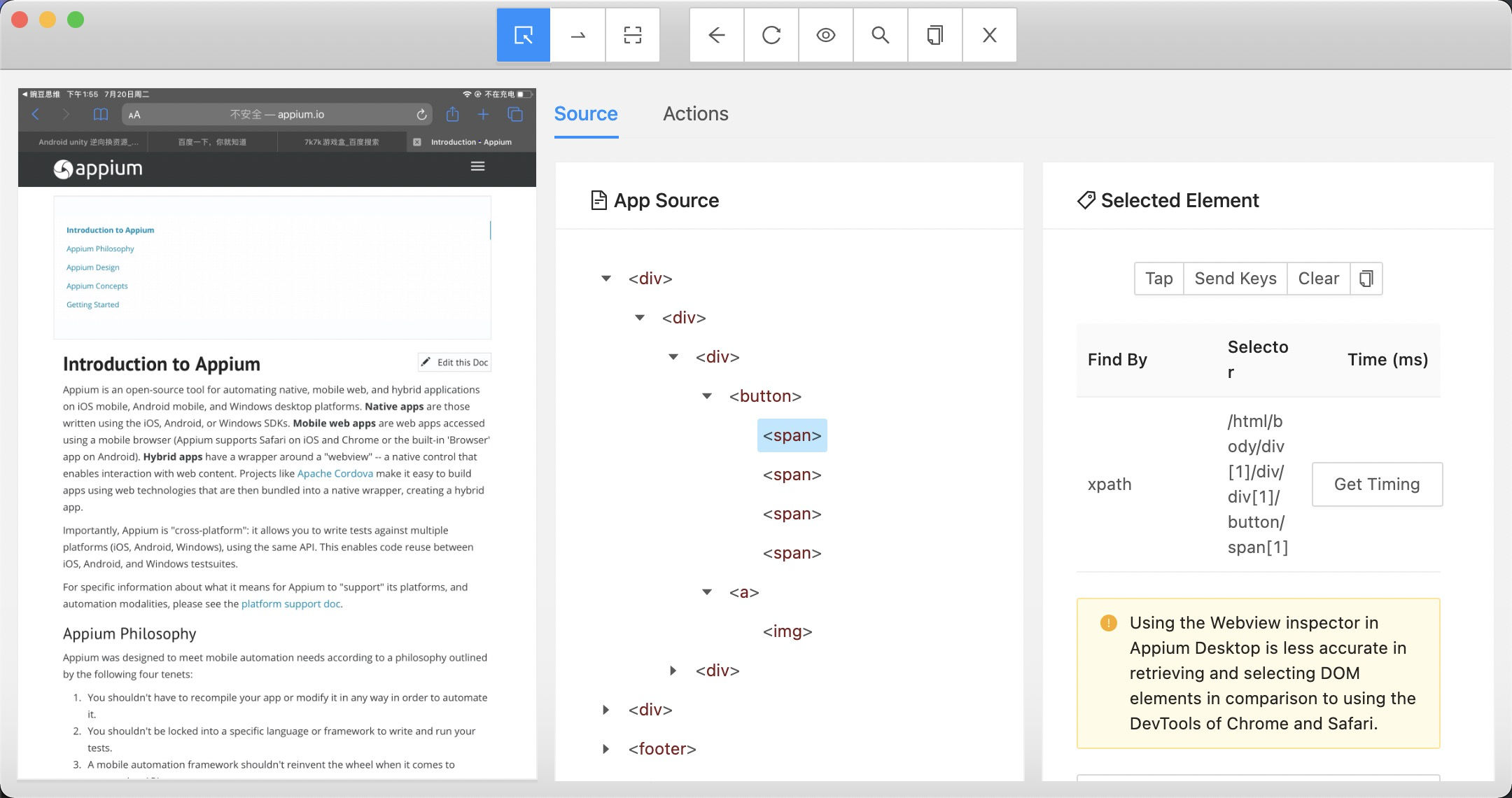
相关配置放到Appium 里面是可以直接拉起Safari 的,但是不能拉起我们指定的App
瞅了一下Appium 关于 hybrid App的测试例子,大多数是使用了Webview 技术来profile 相关HTML Context 内容。这个跟我们现有项目不符,验证到此可以结束了。
结论
Appium 确实是一个很优秀的自动化测试框架,可以通过大家熟知的语言进行相关自动化测试,能够非常方便的提高测试的效率,增加测试结果的可靠性。这一切都需要针对正常的iOS或者Android App , 对于 hybrid App 也有非常不错的测试方式,相关测试代码也是非常的简洁。对于正常类型App 测试,强烈推荐。
iOS 内存分析
iOS 内存分析
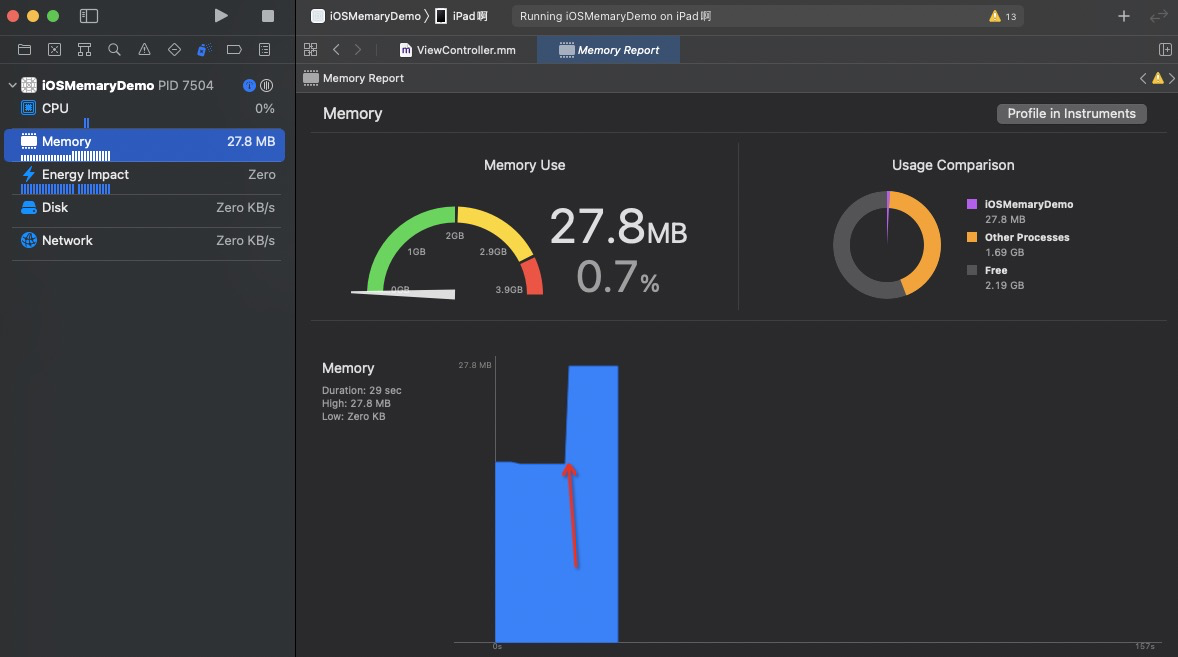
最近在做关于APP 内存方面的分析,去尽量优化iOS 侧 APP 的内存。原本使用的是之前自己掌握的方式,比如 Memory leaks , Memory Allocations 每一项工具都有针对性的内容,在进一步优化的时候发现了原来可以使用终端方式来查询问题。一个对于自己全新的领域。
引述一下关键字:iOS Memory Deep Dive WWDC2018
WWDC2018 , 2018年 。大概如果是苹果开发铁杆粉都已经悉数掌握。但是很多开发者似乎对这块儿知识都了解较少,如何具体使用也不一定都能掌握。我这儿整理一下对自己查找问题中的一些相关性,也顺带做一下总结,提醒一下自己。
前言
利用自己在实际开发中遇到的相关问题来具体讲解如何在iOS中做内存分析,怎样去针对性优化。
怎样去观察内存占用
需要卸载掉哪些内存
怎样观察内存
大家都在Xcode 下经常开发,Xcode Memory gauge 这个界面大家应该都不会陌生
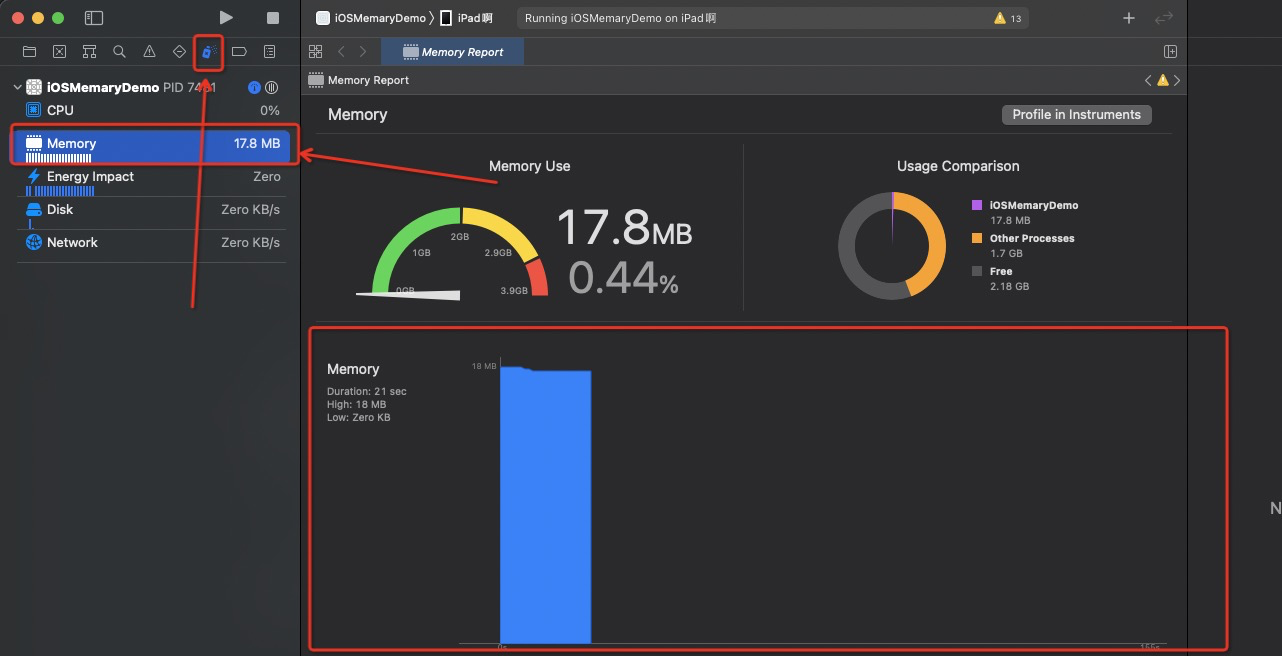
在当前界面,能够提供数字,百分比,内存使用危险程度的通用观察界面。针对于平常查看内存占用大小比较方便,但是对于内存问题,这块儿能提供的内容相当有限。但是能够提示开发者内存占用的波动,从而引起关注。
iOS 内存介绍
iOS Memory Deep Dive 讲了关于iOS 在内存方面的使用和统计方式。提到了在iOS 操作系统中,内存的统计方式是按照分页的方式。内存又会被细分为 物理内存 和虚拟内存。 APP 的运行是一定要基于内存之上的,物理内存和虚拟内存的主要作用如下。
物理内存:设备运行时为操作系统和各种程序提供临时储存空间
虚拟内存:为每一个进程提供了一个一致的、私有的地址空间;其主要作用是:保护了每个进程的地址空间不会被其他进程破坏,降低内存管理的复杂性。 虚拟内存是进程运行时所有内存空间的总和,并且可能有一部分不在物理内存中。
iOS系统是按页分配内存的,每个page通常是16KB
1 | Memory in use = Number of pages * Page size |
iOS内存可以分为clean memory和dirty memory。当用户(也就是程序员)申请分配内存时,系统只会对这块内存进行标记,这时只会分配虚拟内存,而不会分配物理内存,此时内存是clean memory。当对这块内存进行数据填充时,才会分配物理内存,内存变为dirty memory。
1 | Memory Footprint = Dirty Memory + Compressed Memory |
针对内存问题,我们考虑的重点也是去减少 Dirty Memory
具体查找步骤
根据已知的信息,尝试去实践一下如何查找内存消耗,这次使用命令行方式。
以第一张图 27.8M 为例。首先修改 iOS Scheme , 勾选 Malloc Stack Logging 并选中为 Live Aloocations Only
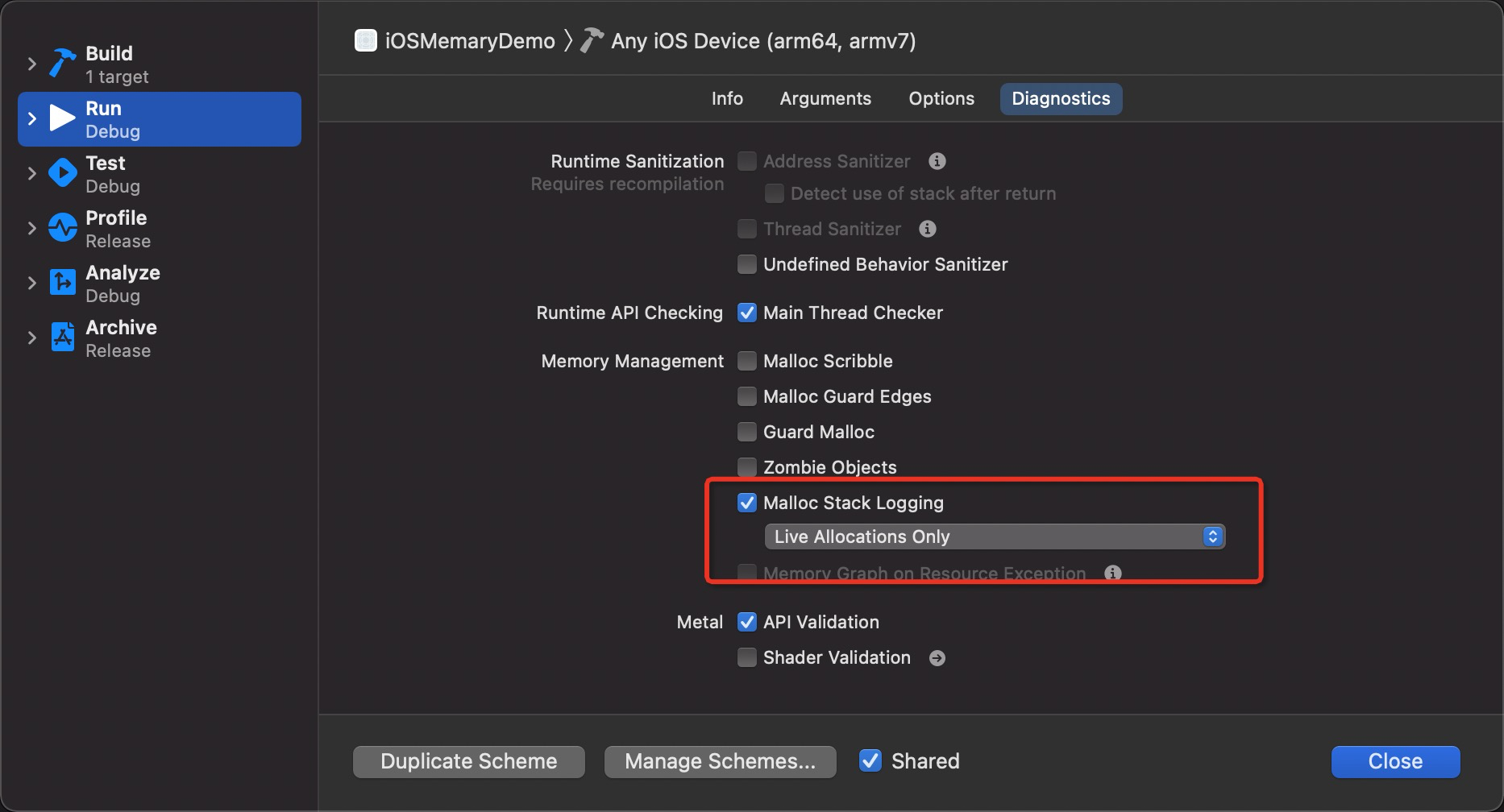
然后就是运行中等待时机到来,点击Debug Memory Graph 得到内存图。可以通过 File --> Export Memory Graph到处文件到指定位置。
1 | #终端执行下面代码 |
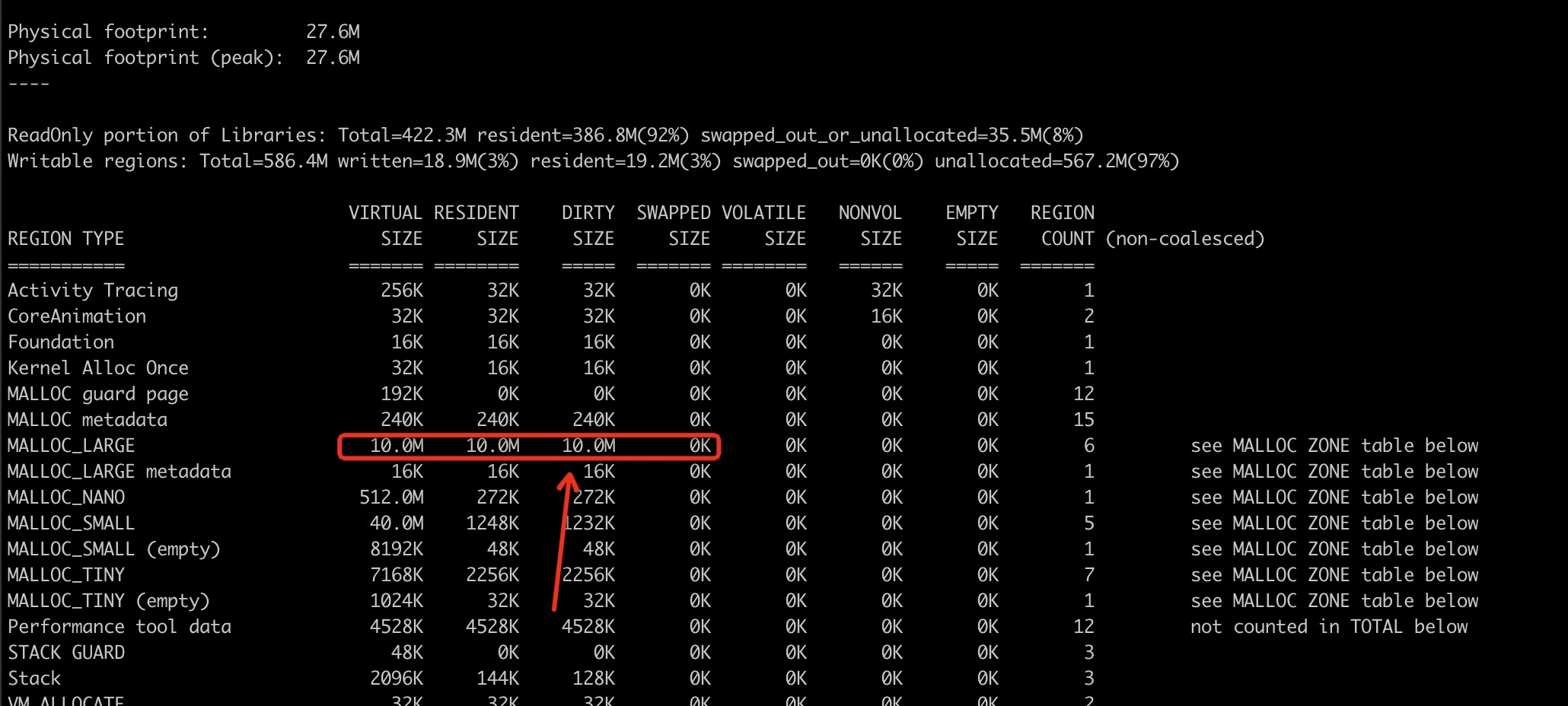
从我们已知的信息可以知道 , Dirty Memory 是我们关注的重点。于是发现了 REGION TYPE 是 MALLOC_LARGE
1 | $ vmmap -verbose memory.memgraph | grep "MALLOC_LARGE" #获取详细的关于内存分配的 在归属于 “MALLOC_LARGE” 这里的内容 |

从图中我们可以容易的发现,内存地址为 0x1146e4000 。 在这样的情况下,我们可以借助于另外一个命令 malloc_history
1 | $ malloc_history memory.memgraph -fullStacks 0x1146e4000 # 获取地址块儿的堆栈信息 |
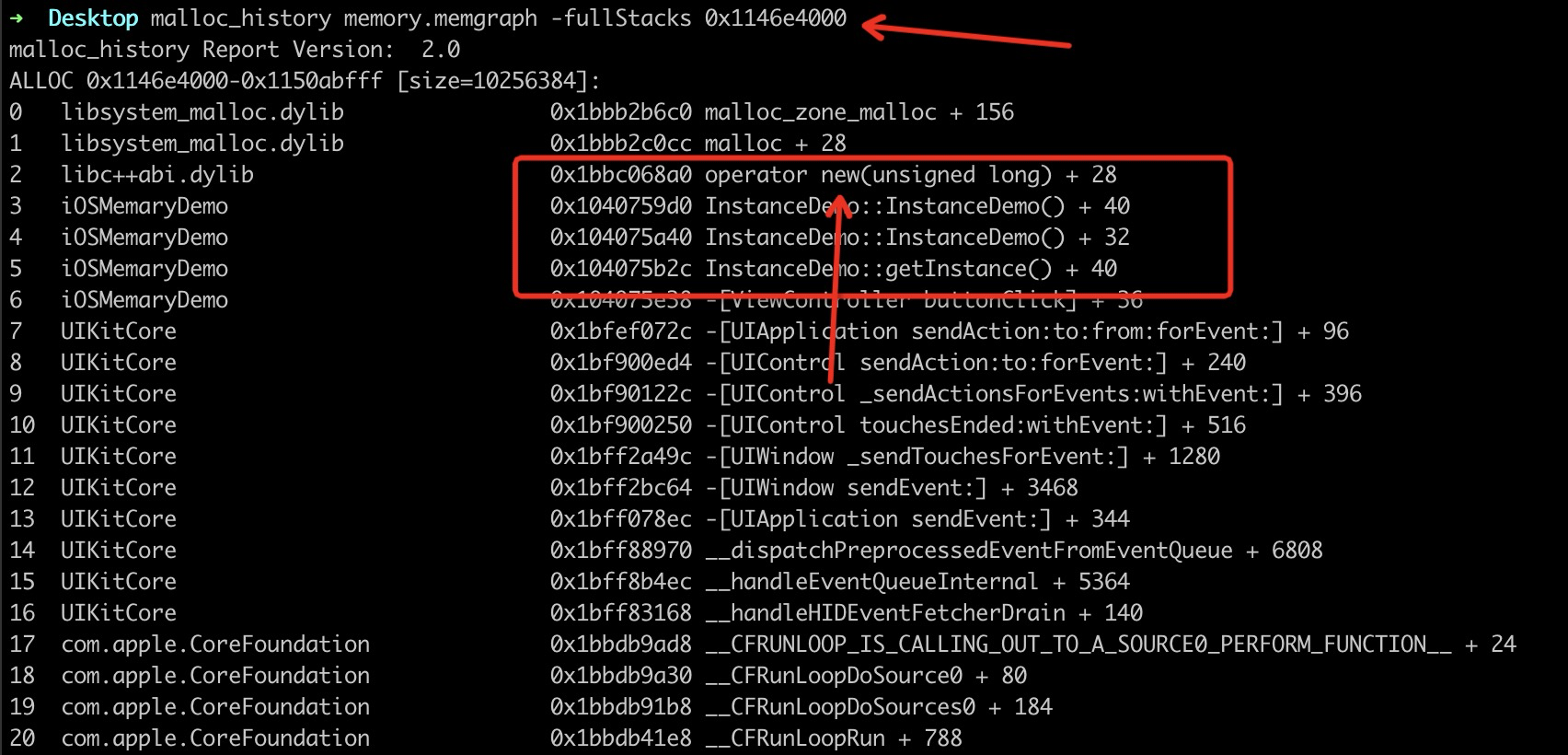
根据我们查到的调用堆栈,我们发现是因为 new 操作,导致了内存分配,源头应该在于 InstanceDemo 这个类的构造函数。
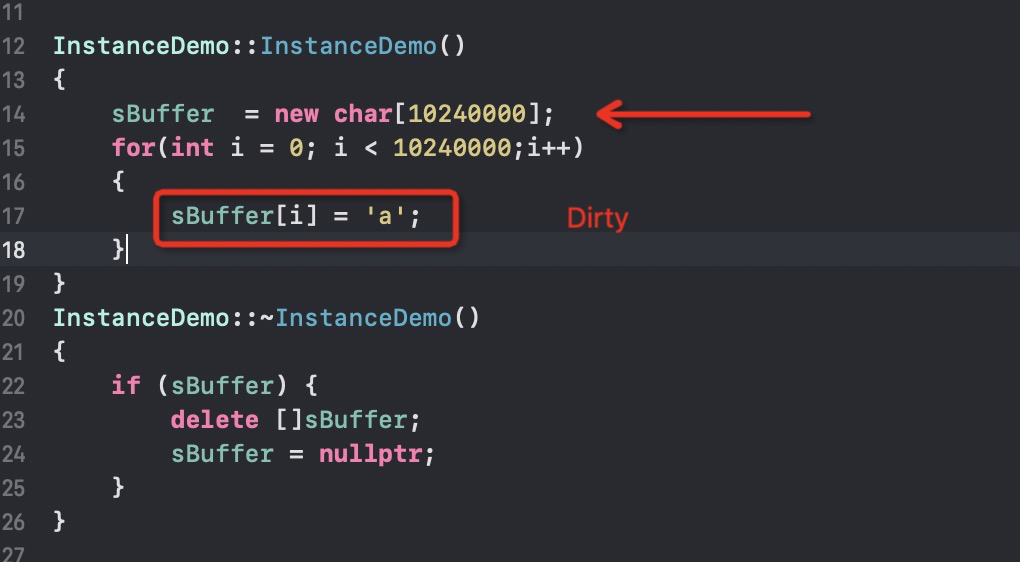
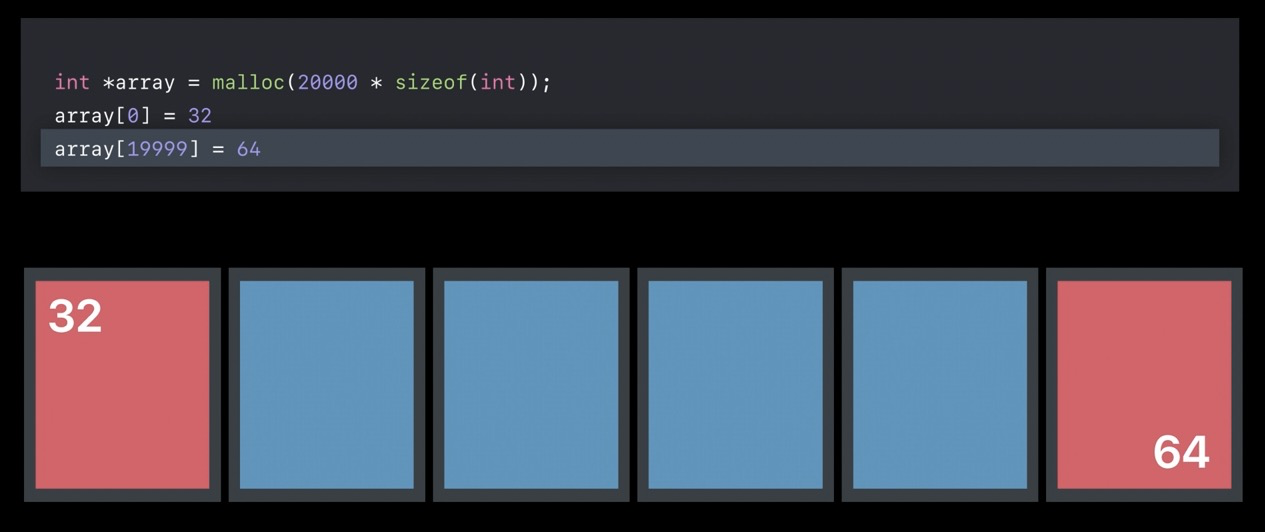
贴上源码,是这里引起的内存分配无疑。我们同时也发现,Dirty memory 也是 9.8M. 如果我们不给数组赋值呢?
我们注释掉数组赋值,重新走一遍儿上面的流程。
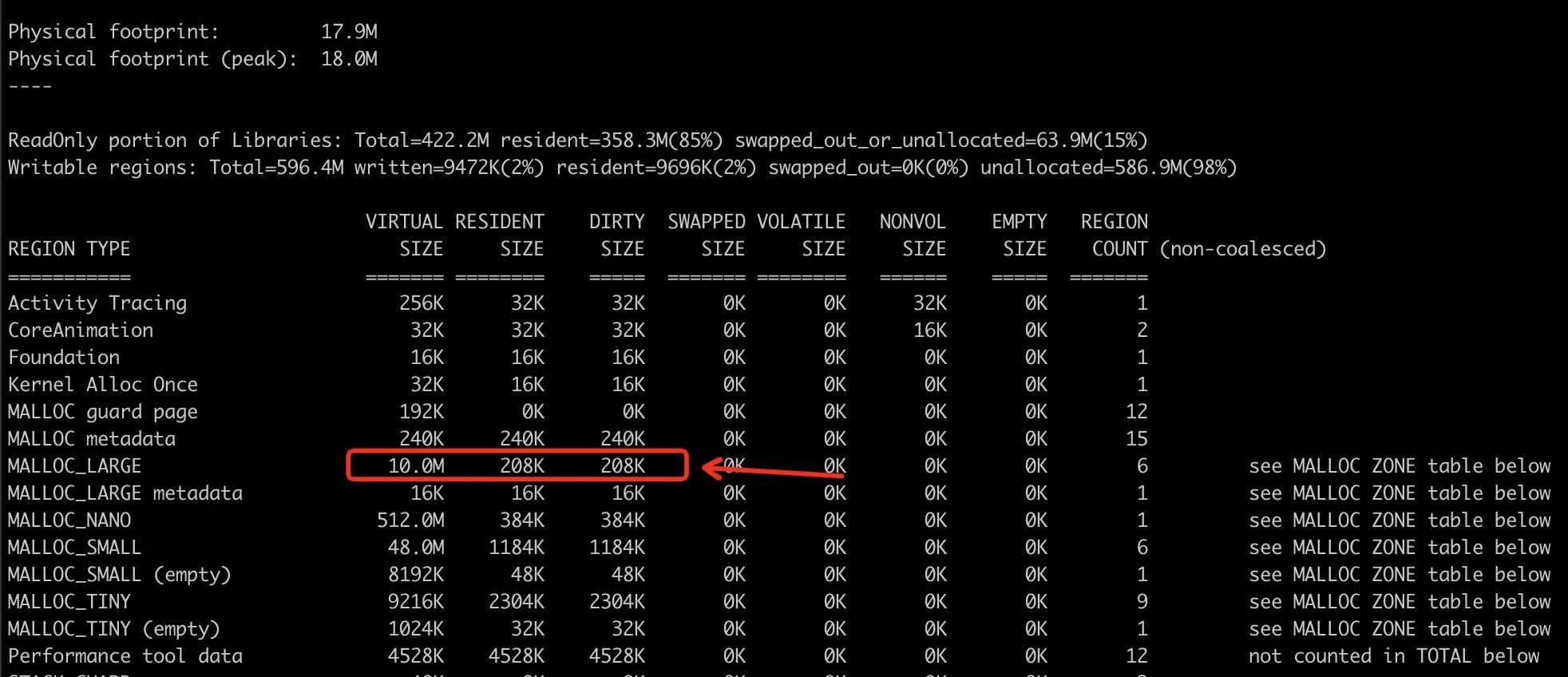
于是发现了,同样 MALLOC_LARGE 中的 VIRTUAL SIZE 是 10M , 但是DIRTY SIZE 只剩下了 208K
如果我们细跟入进去会发现
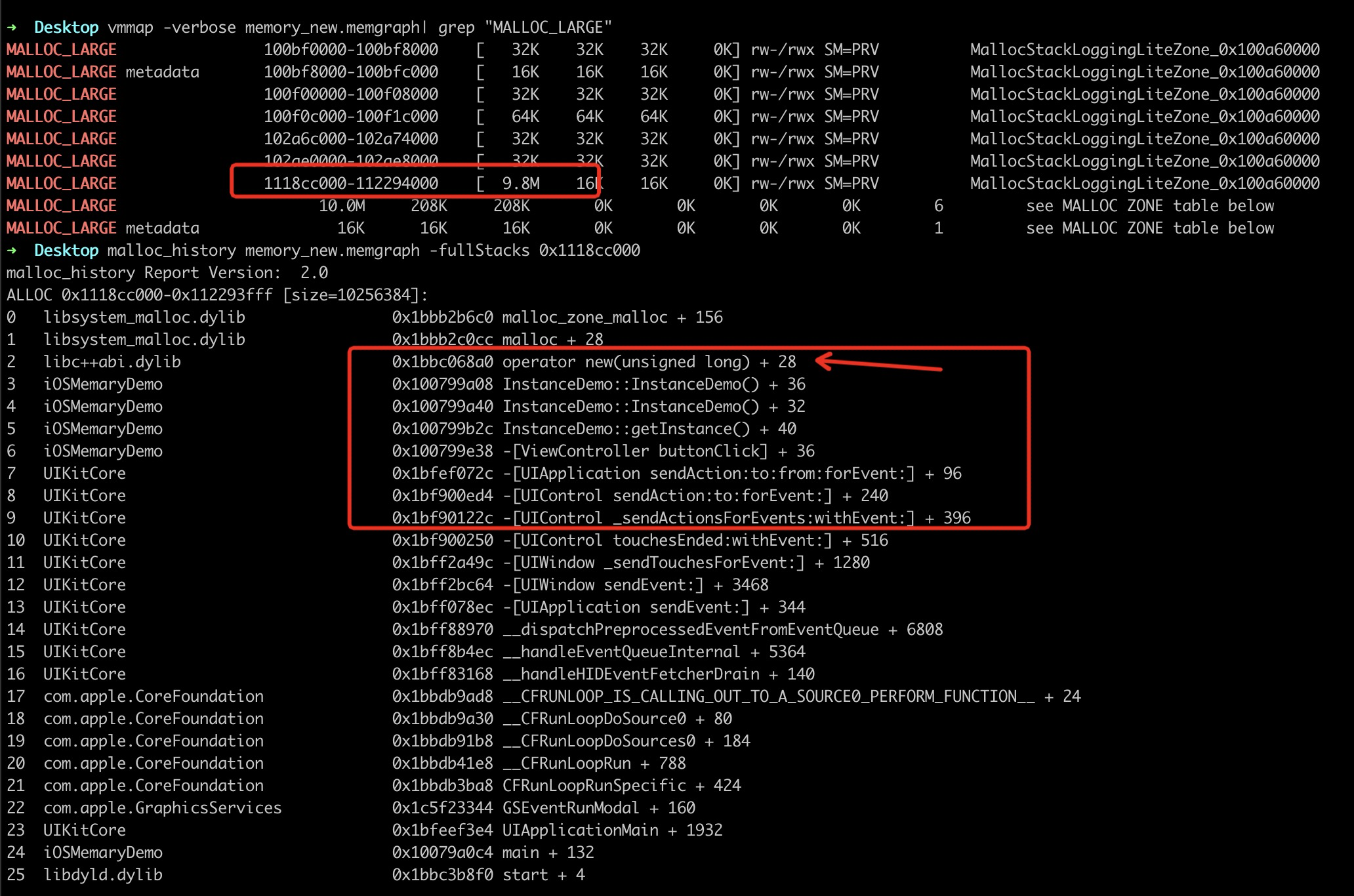
是同样能够查到内存分配的位置。但是因为只有内存申请,没有使用,分配的区域被放在了虚拟内存,所以Dirty MEMARY 并没有相应标记。
在查询内存问题的时候还有另外一个命令可以使用,就是
1 | $ leaks -traceTree 0x1118cc000 memory_new.memgraph |
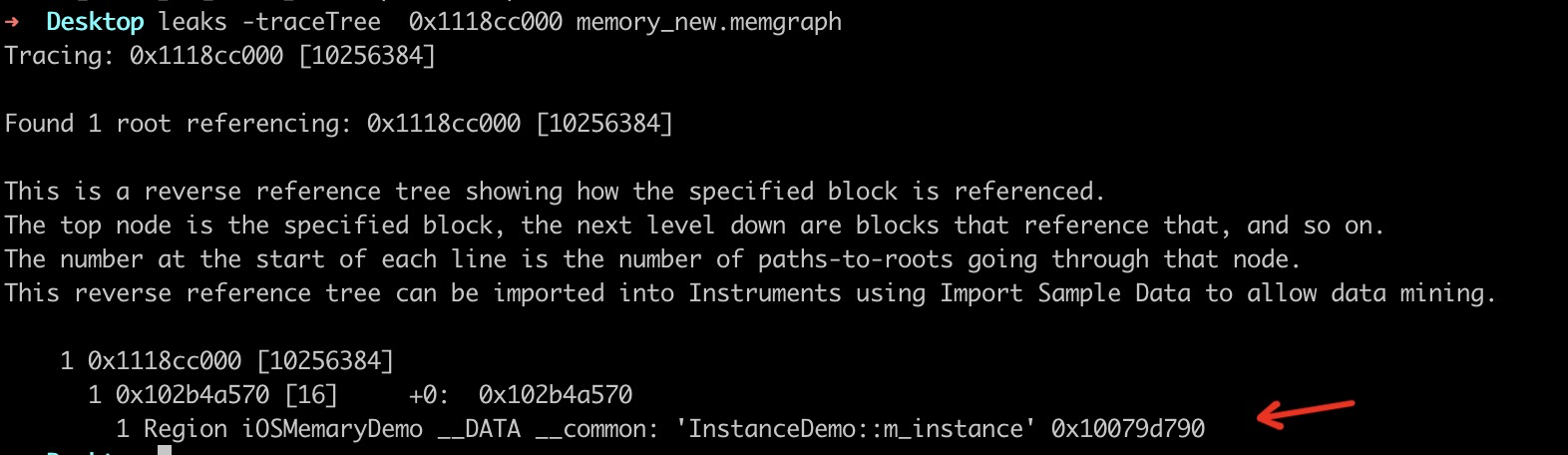
通过这个命令可以知道 m_instance 被持有引用,可能会出现内存泄漏。
Demo 依旧会提供,主要对内存如何分析和查找可能性提出一些方法。 我们同时还可以通过Xcode 提供的 VM Tracker 等工具用来具体指向我们怀疑的点。一般来讲,图片资源占用的内存会比较大,如果作为优化的方向,首选见效处理就是规范化图片资源。
Laya Native 性能分析和改造笔记
Laya Native 性能分析和改造笔记
分析和修改步骤:
1、使用laya编辑器 , 2.1.0 版本的,导出生成 2.1.0 版本的ios 工程为基础
为了验证编译导出的laya 二进制文件能否放入到低版本,先对2.1.0 版本ios 工程做了以下修改
改动部分如下:
- 替换laya脚本导出的 libconch.a 文件
- 替换高版本(2.11.0)apploader.js , index.js ,挪动版本 webglPlus.js 到低版本工程
改动后代码可以直接正常运行。
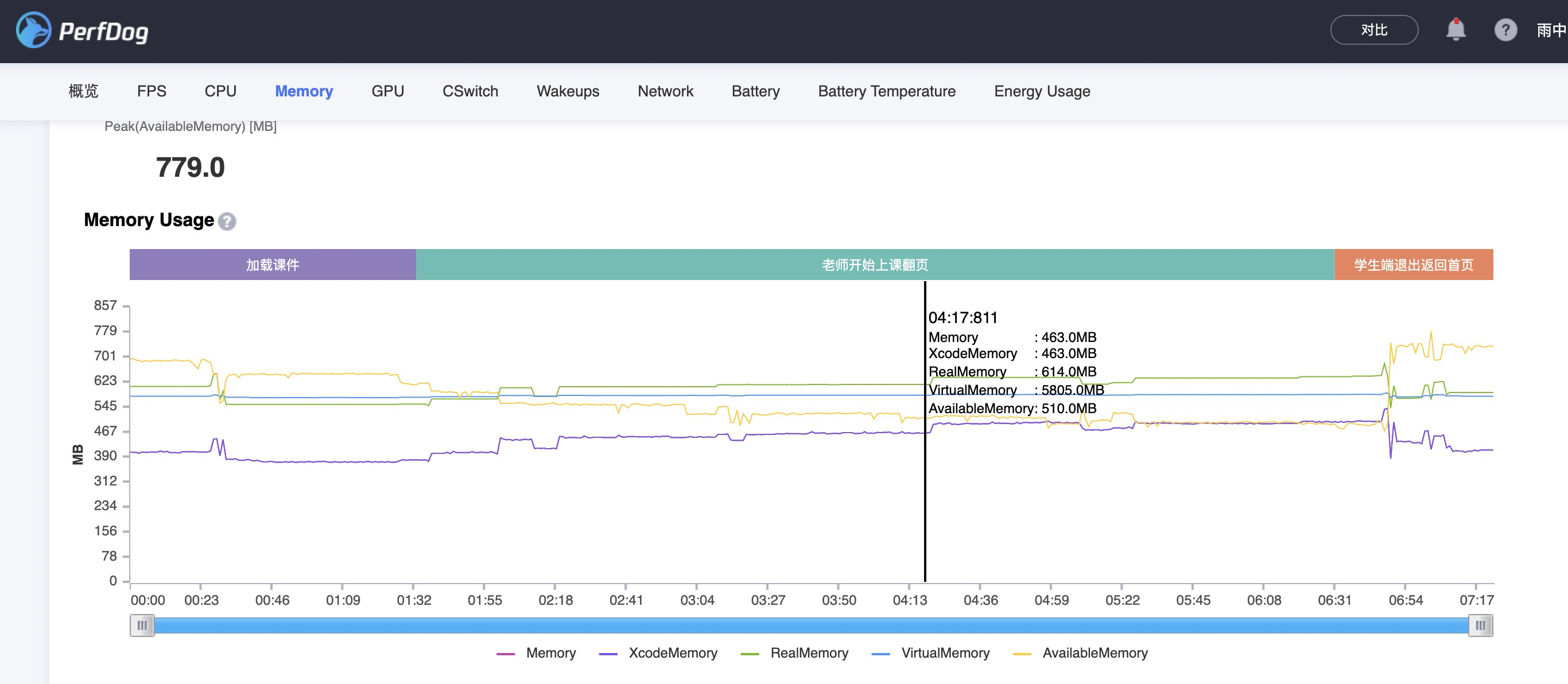
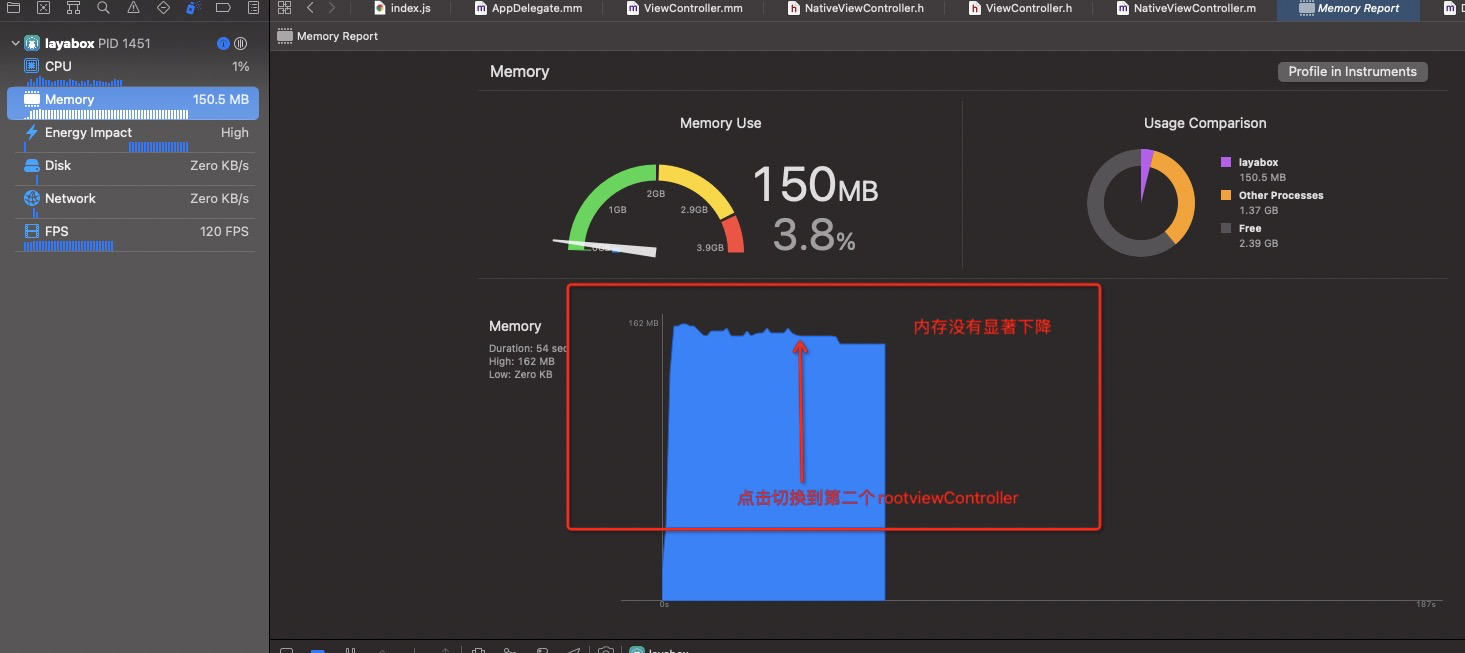
profile 内存使用情况 (更换后,游戏运行状态) 170M (现象,也同时证明laya已有js 代码可以直接运行在Laya 高版本运行环境)
问题:
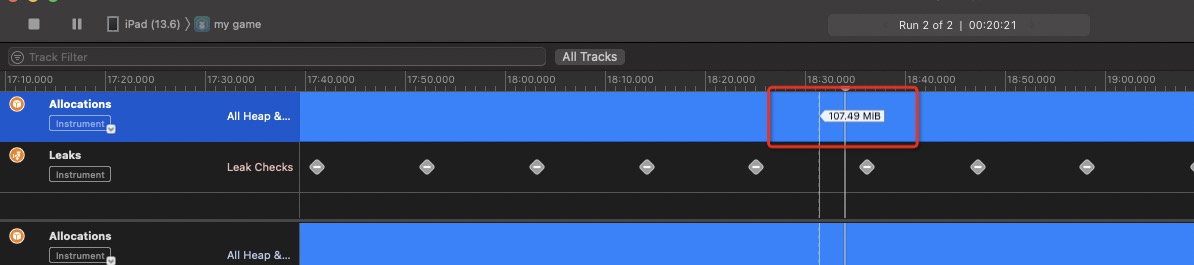
在直接更改iOS源码,强制卸载laya部分,表现如下,内存并没有如预期下降。
在profile 里面去查找还持有,存在于内存的一些对象,可以发现如下(两个占用内存的大户)
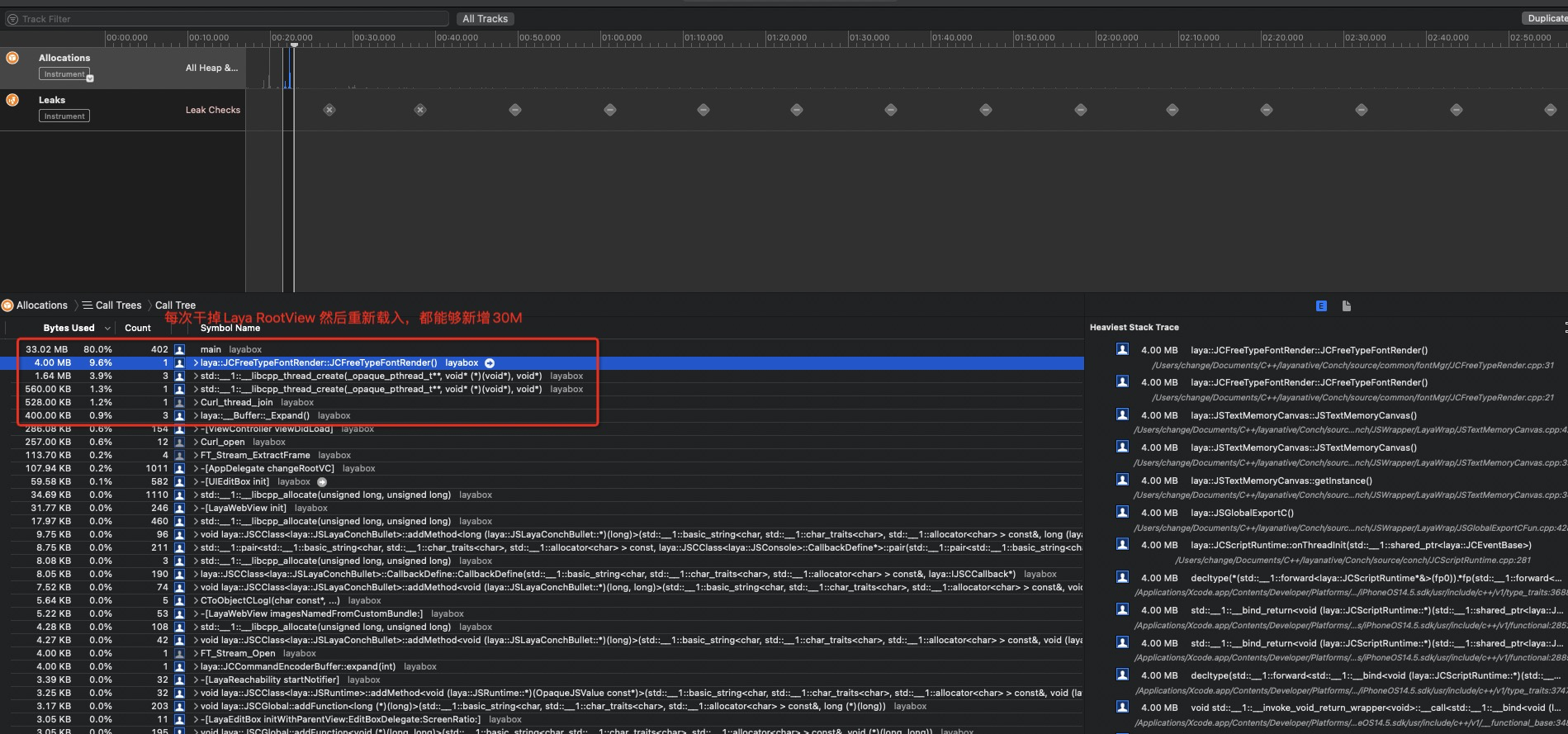
把相关退出代码搬运到 laya 提供的项目工程中,通过debug方式profile ,能够看到每次重新进入laya 内存部分被重新分配了 30+ M (每一次都会增加,认定引擎侧出现内存泄漏,在于C++或者ObjectC)
比如可以很直观发现下面的泄漏。
优先解决内存占用大户,发现特征是如下,不能指向具体的代码片段,但是也提供了相应的信息,libglxxxx 推测是在OpenGL 侧。(可能是C++ 持有,属于重点怀疑,但是这个库又是iOS自己提供,所以ObjectC 也不能排除)
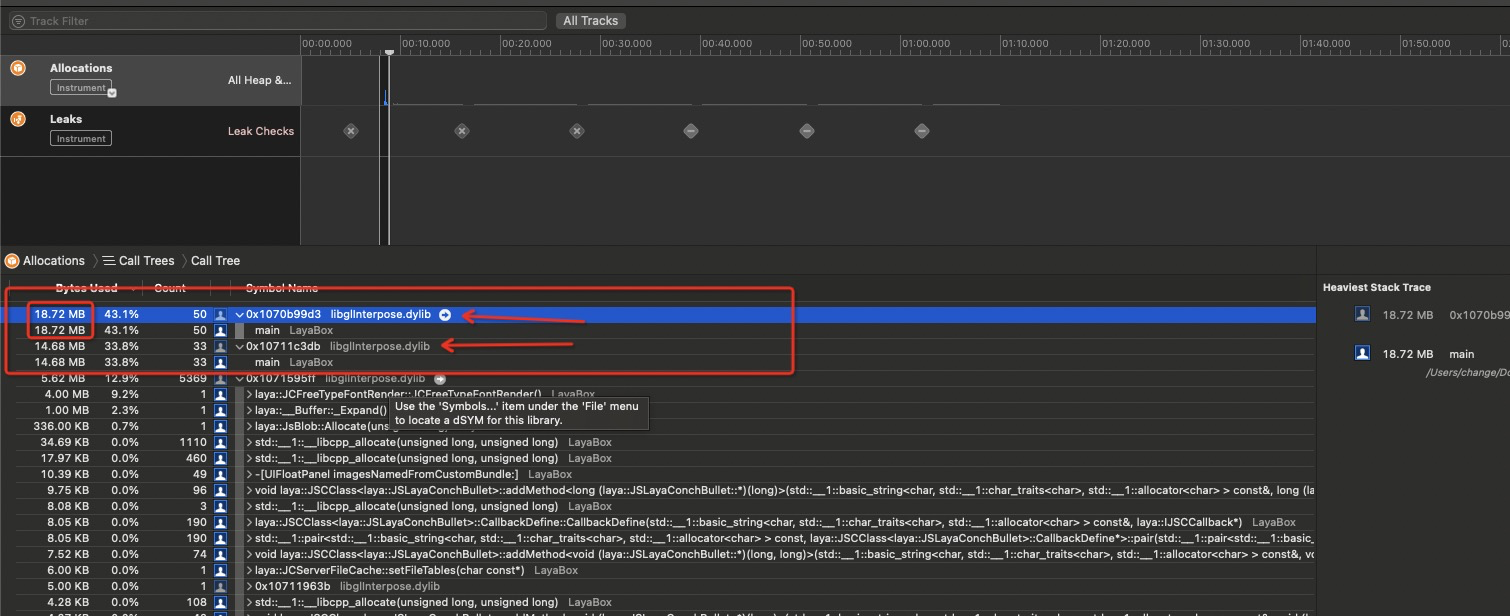

在一次profile 时候,在资源载入的时候发现了JCLayaGl 和texture2d 的字段,所以怀疑为C++ 本身内存泄漏的可能性又在加强。libglxxxx 这个东西依然存在,可以先做排除法,先不去管texure2d这块儿。
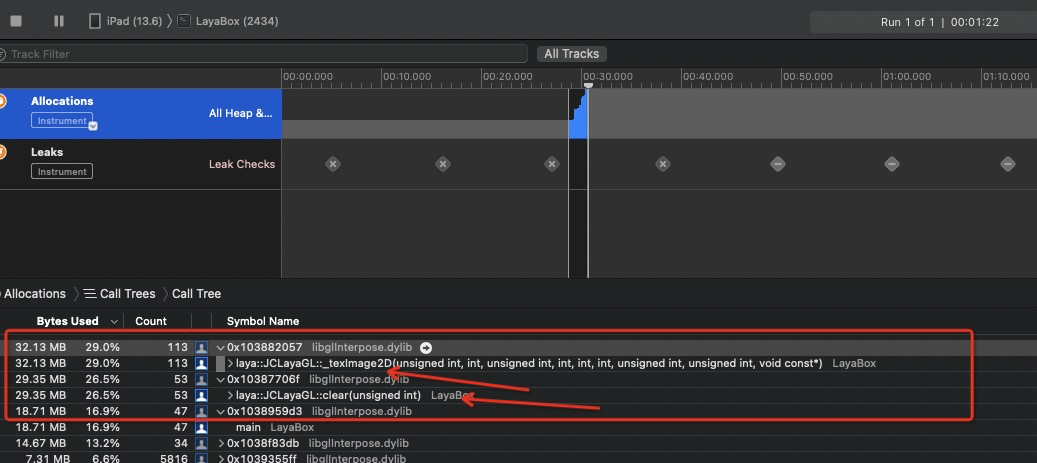
不使用texure2d的最直接方式是不给图片资源,于是,更换为无图片资源小游戏demo,测试如下
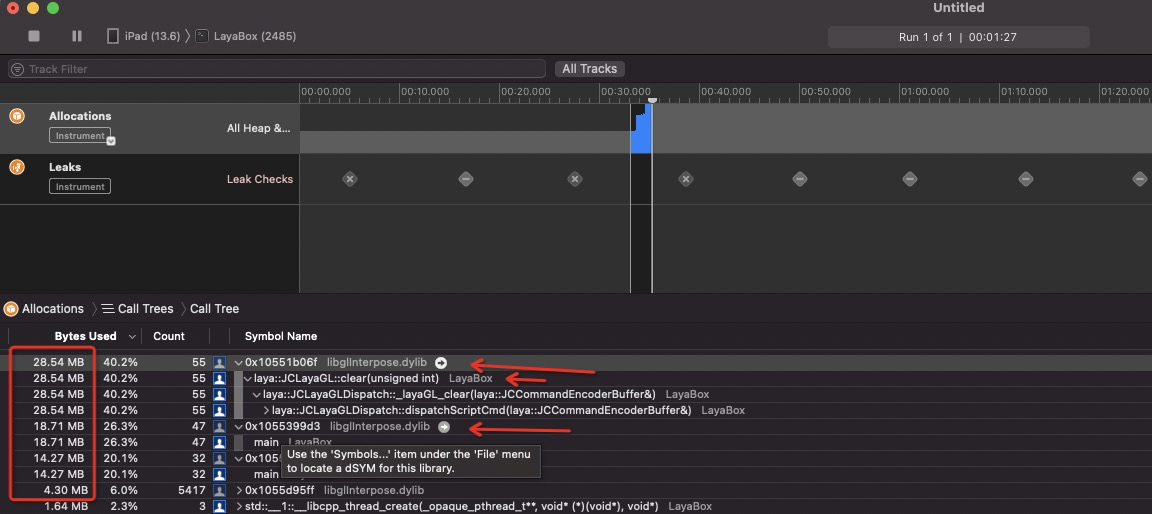
依然存在大量的 Gl 字段, 而且还能看到很多 allocated pair to attach … 这货又好像是iOS的内存泄漏
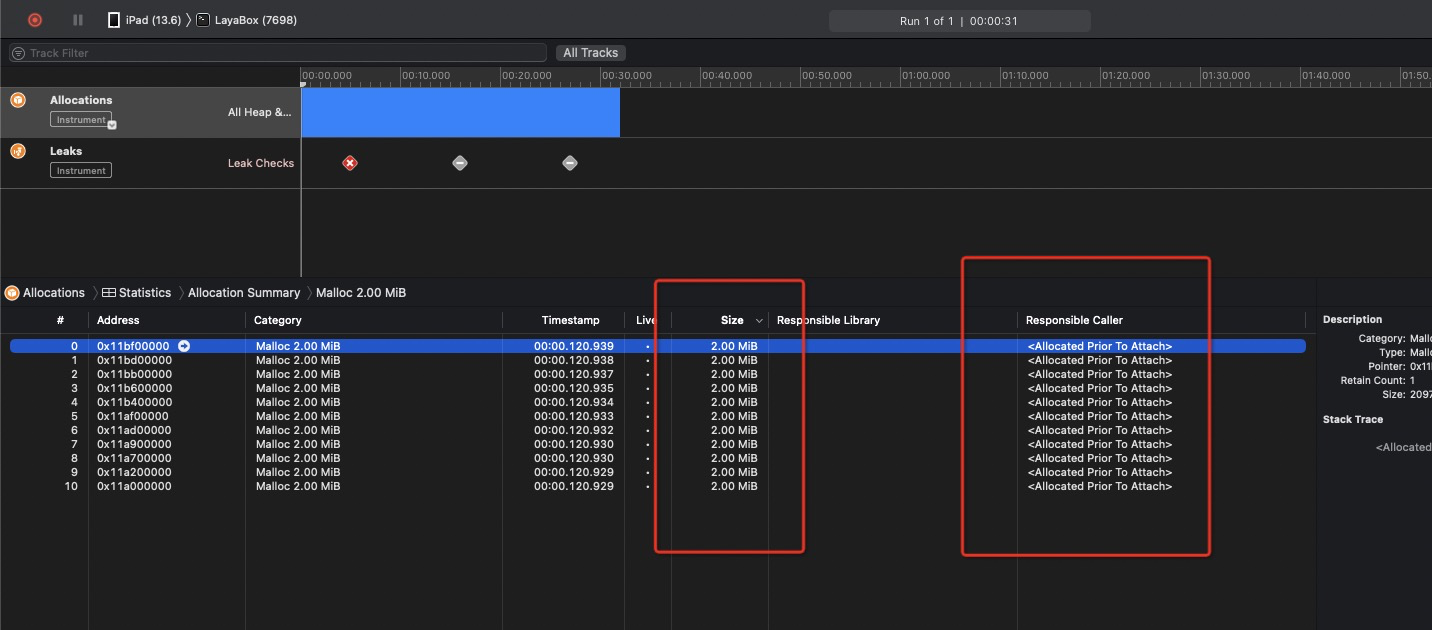
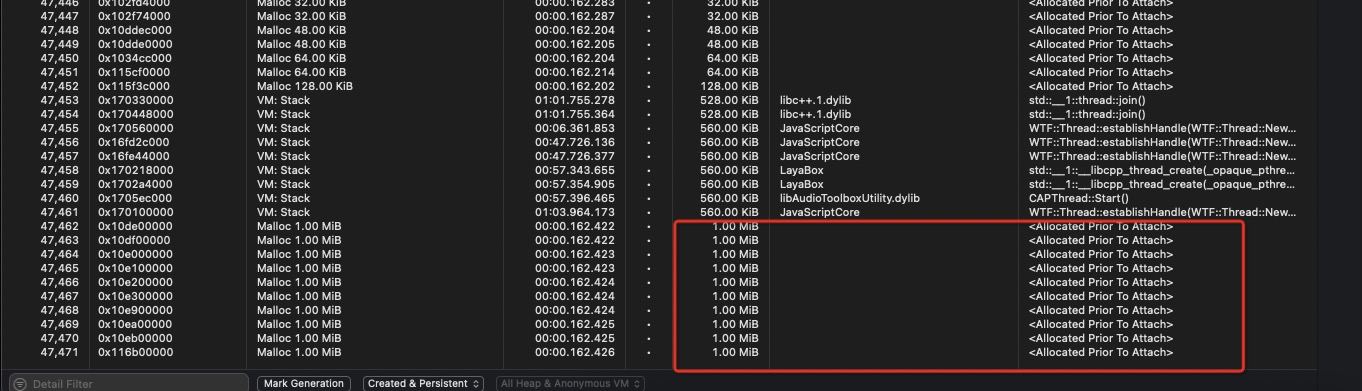
所以基本认定,在iOS Object C 侧,卸载部分存在内存泄漏,在C++侧也大致会存在相应的内存泄漏。那么下面面临的问题就是如何修复。
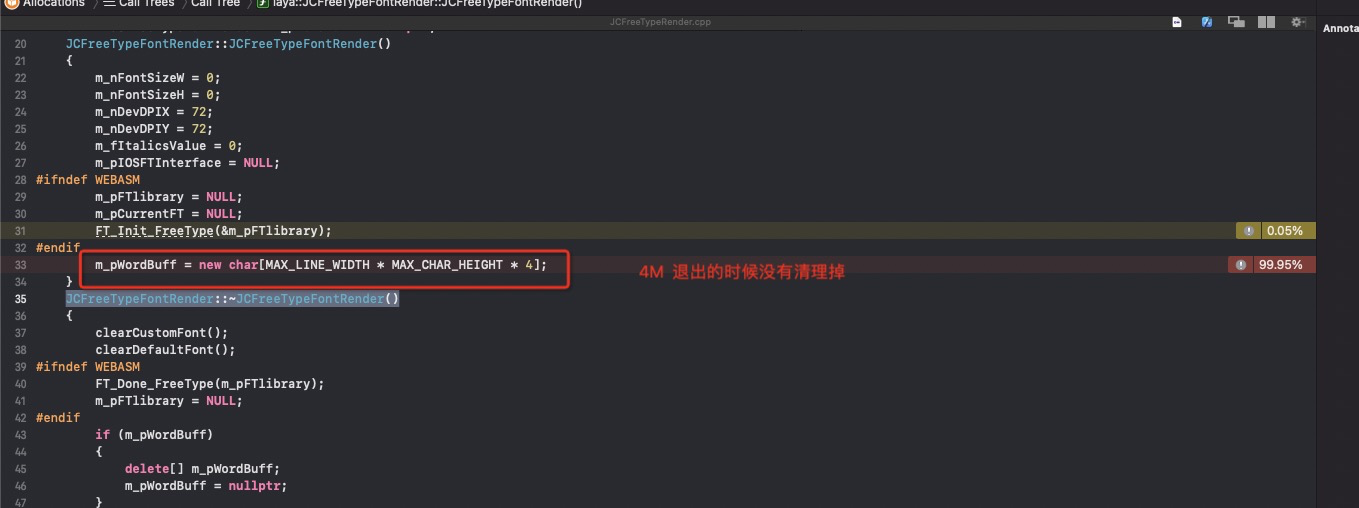
C++通用内存泄漏部分基本是在于 Init 或者 构造函数 中 new 出一些对象,在析构时候没有干掉,导致一些内存常驻。
Object C 里面也有C++ 类似的地方,alloc 出对象,然后强制引用,导致对象不能正常释放。
所以基本解决的思路就有了,下一步,干活验证。
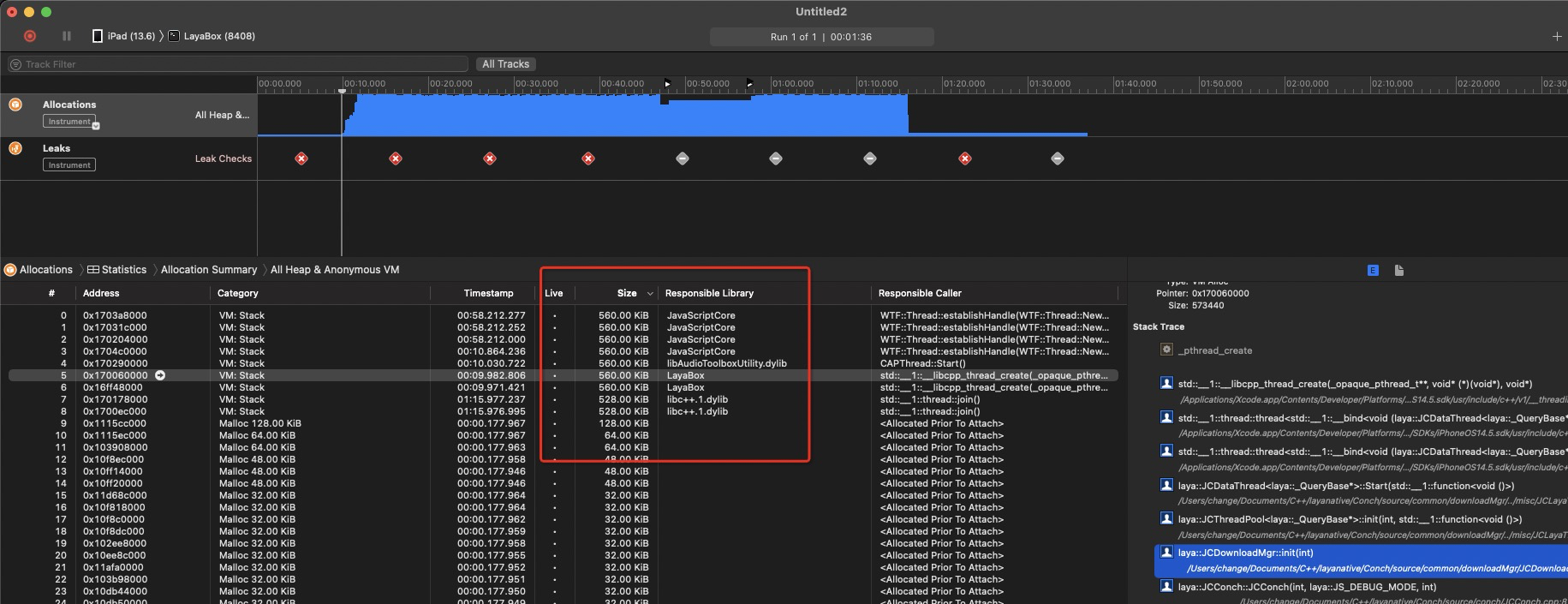
ios 如下图,现有学生端 profile 内存部分,也能找到在上面魔改的Demo 工程中出现的内存消耗大户,所以laya 本身存在 destory 接口,但是内部逻辑却没有做到位。既然有,那么我们强制析构对象的时机和入口就很明确了。
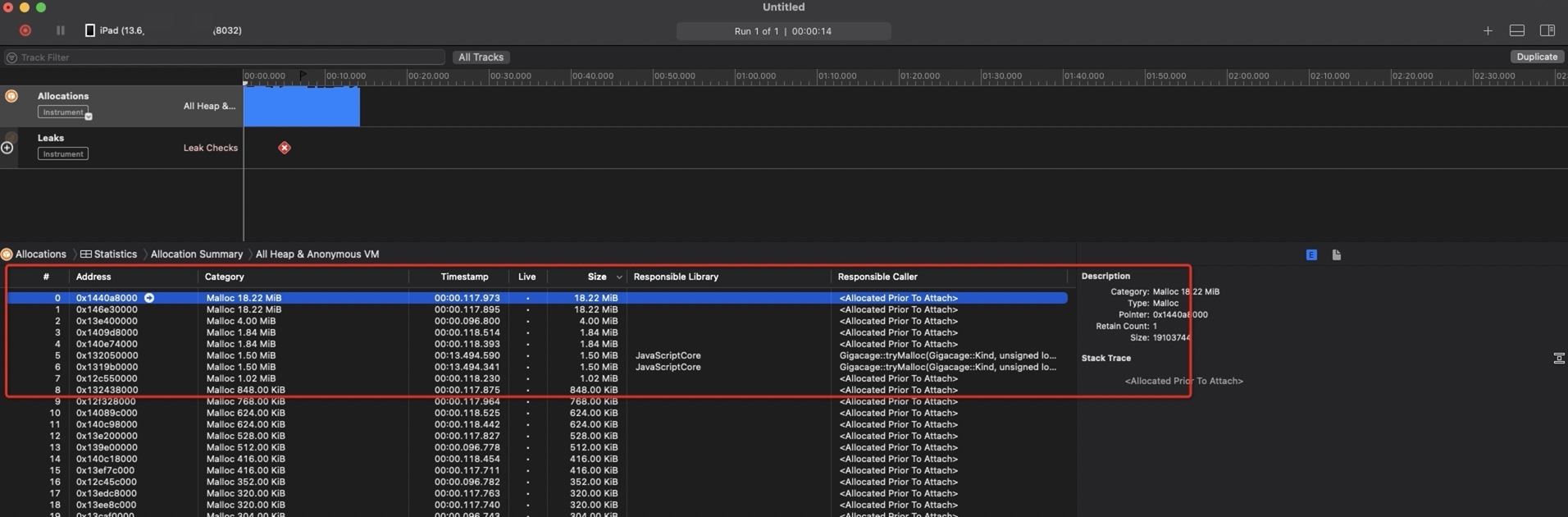
测试内存和性能比对:
替换修改好的laya二进制到学生端 卸载前
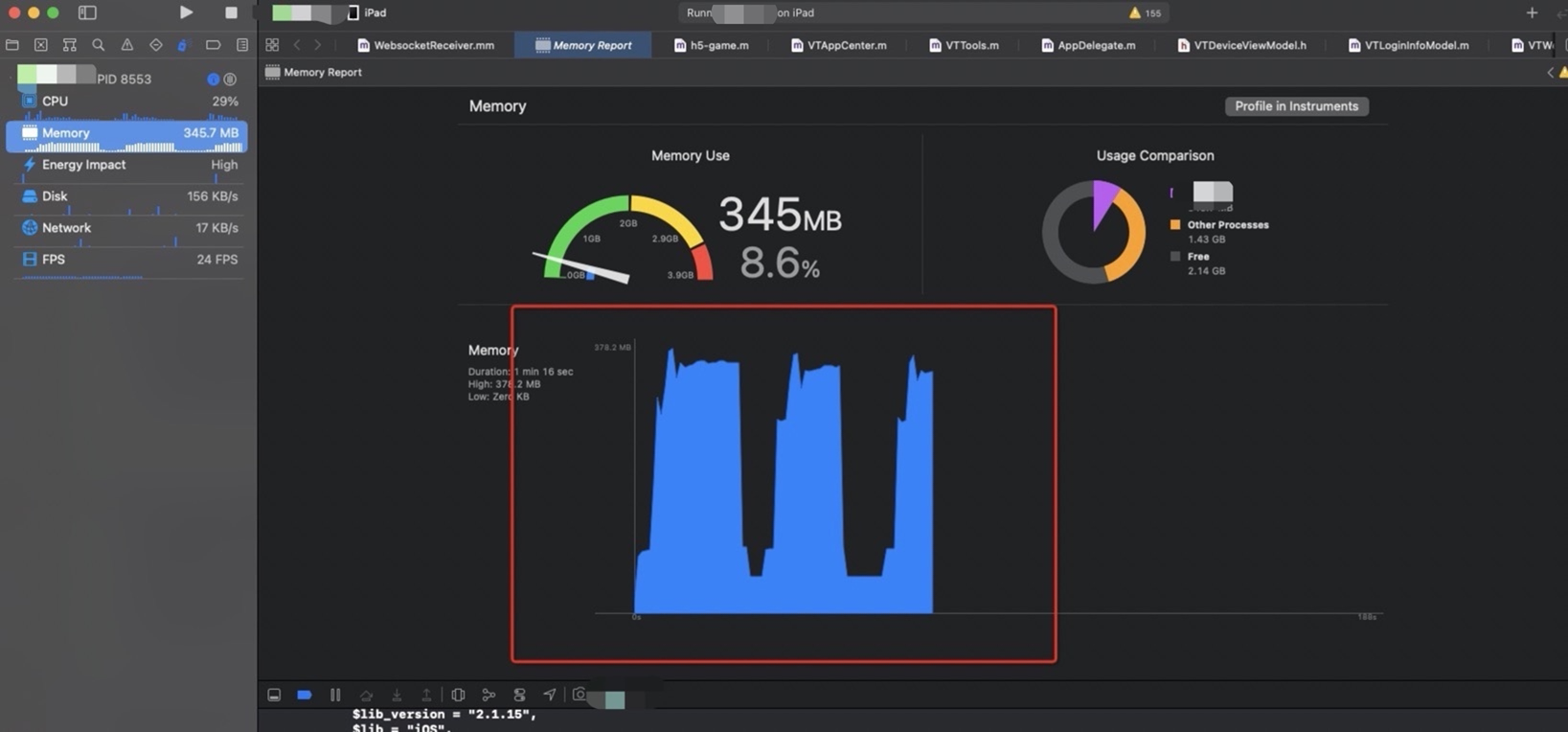
卸载后
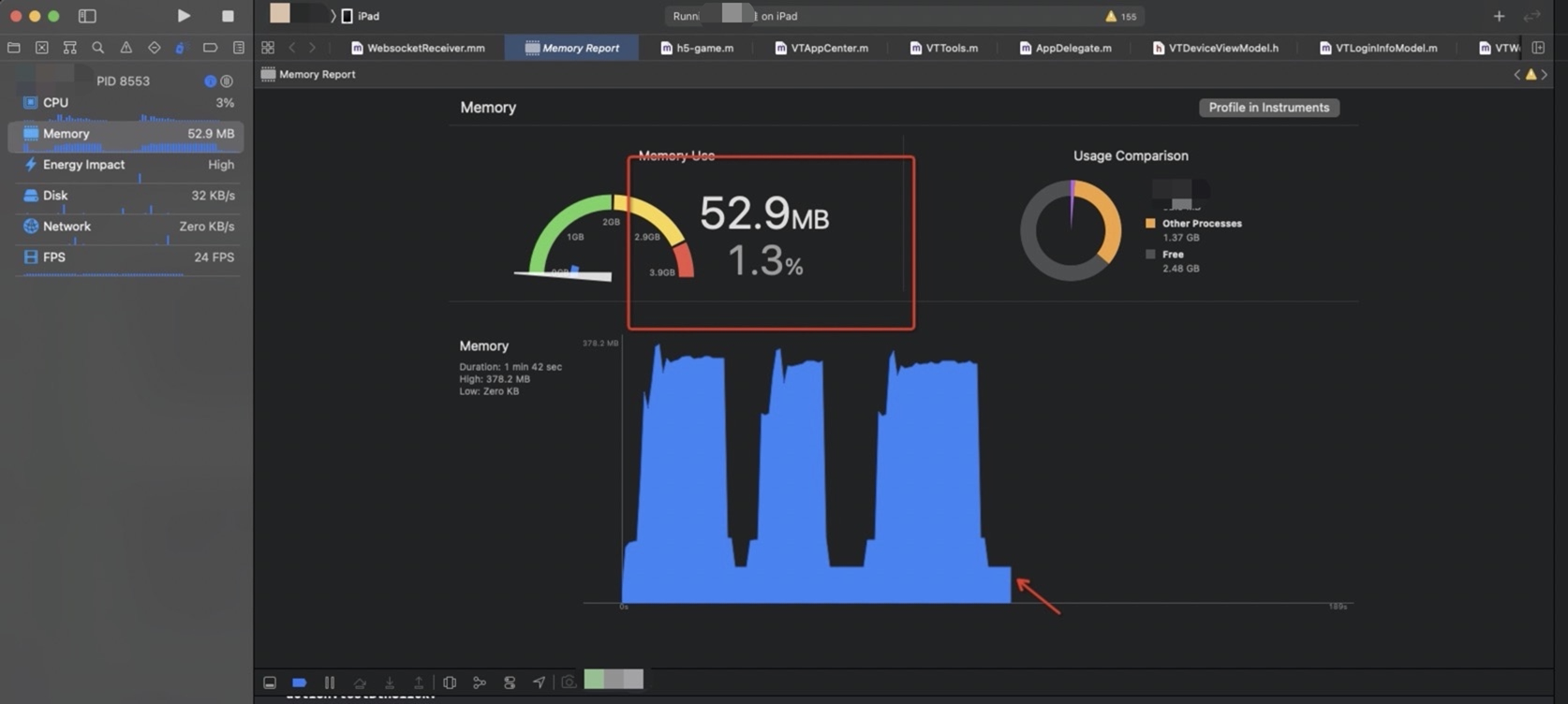
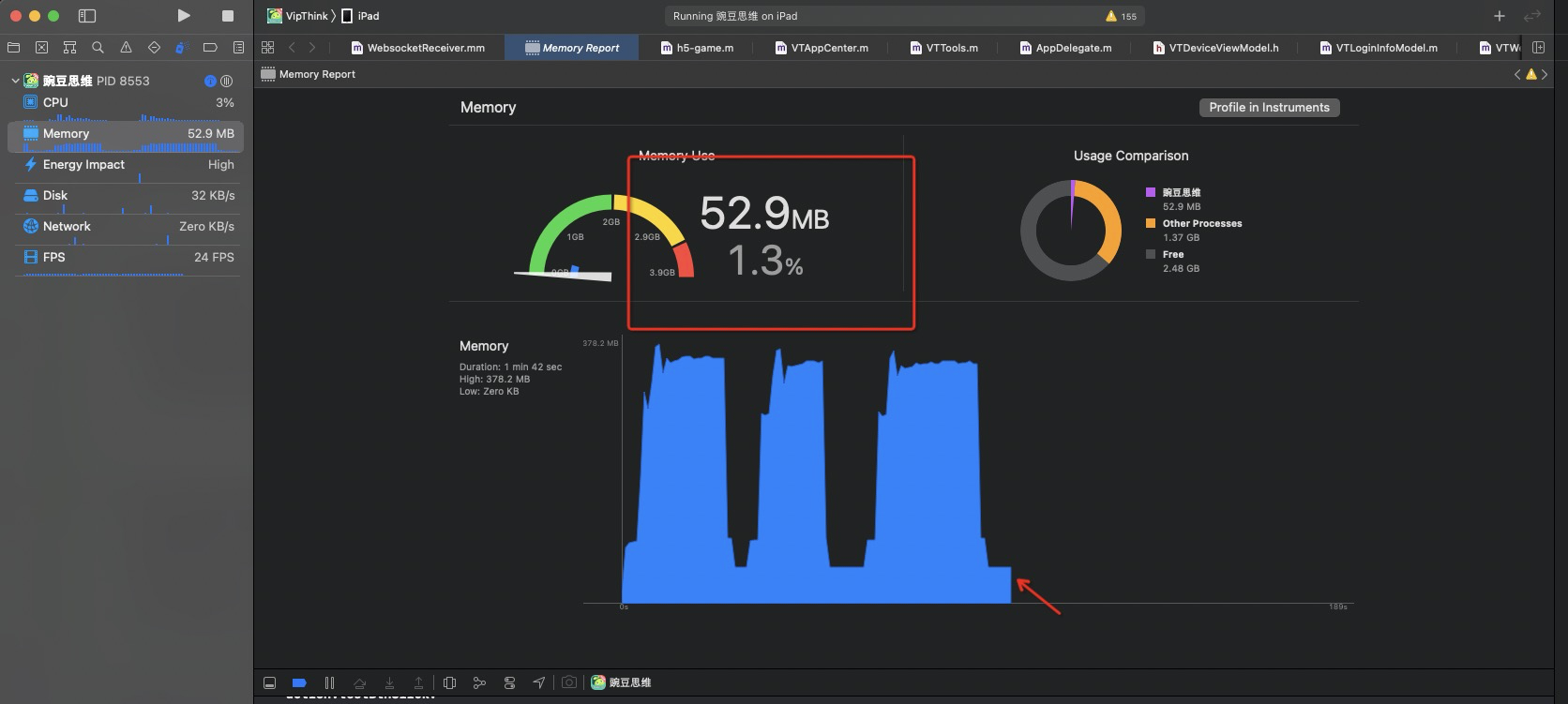
明显看到内存能够降下去!!!
具体内存和性能对比
laya 两个版本运行时内存比较
新版本
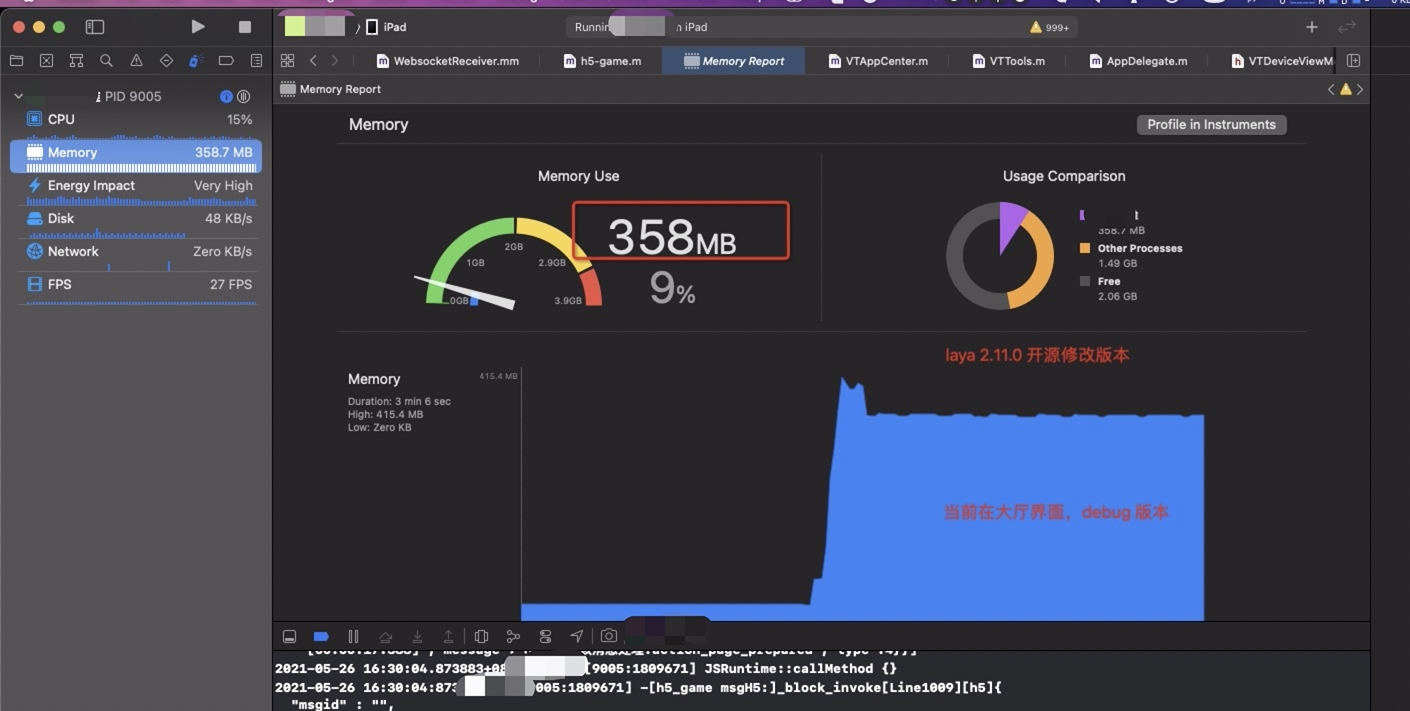
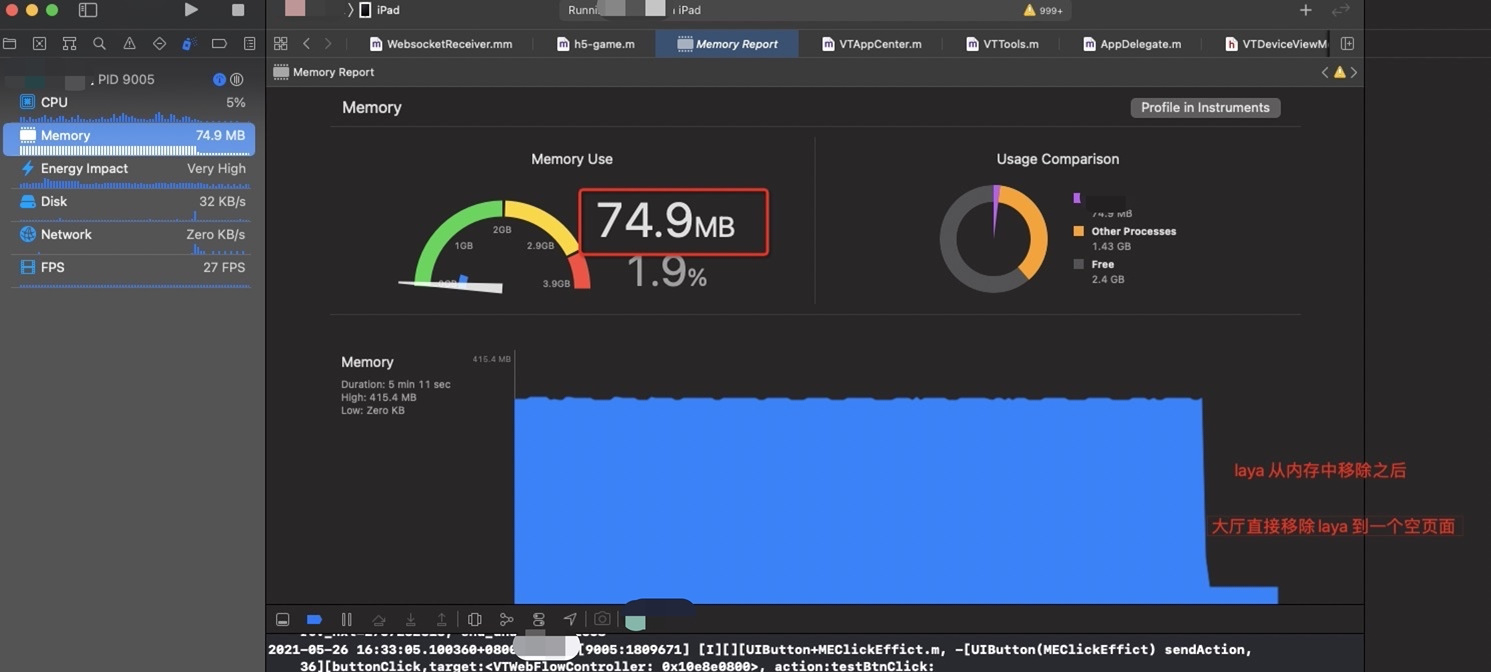
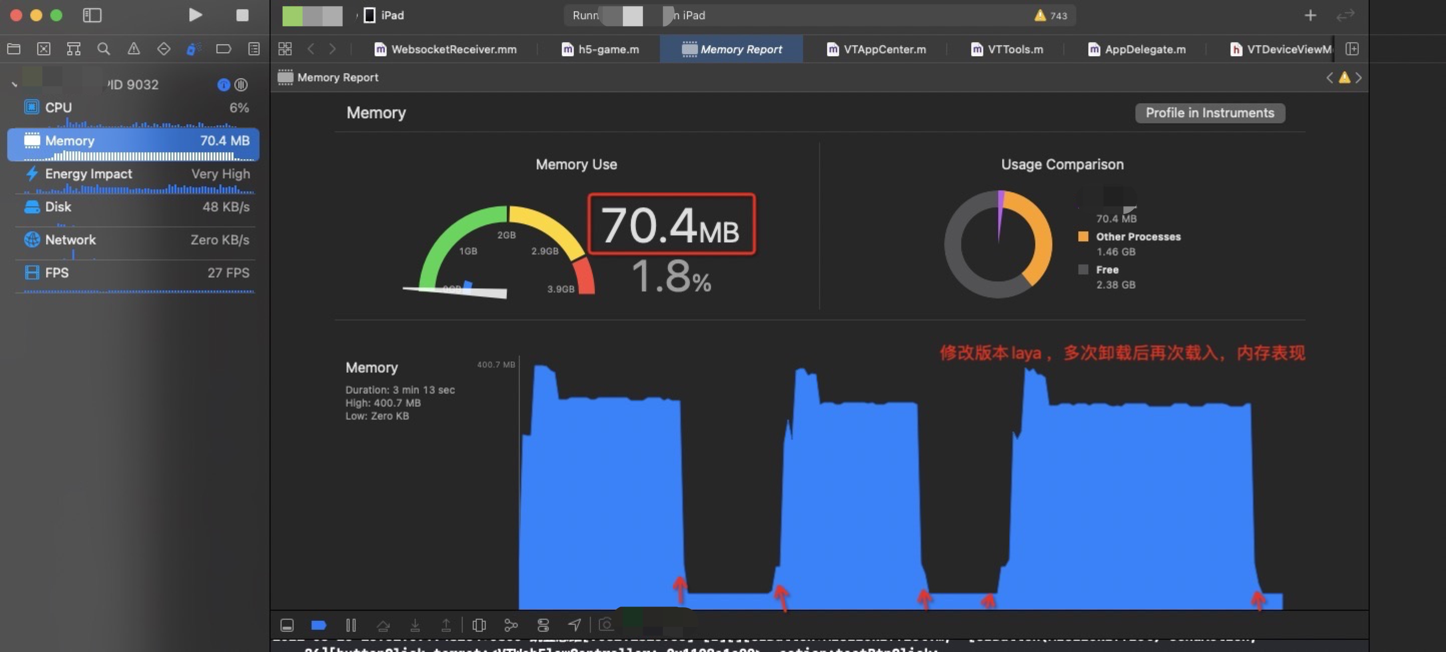
旧版本
旧有的占用内存量
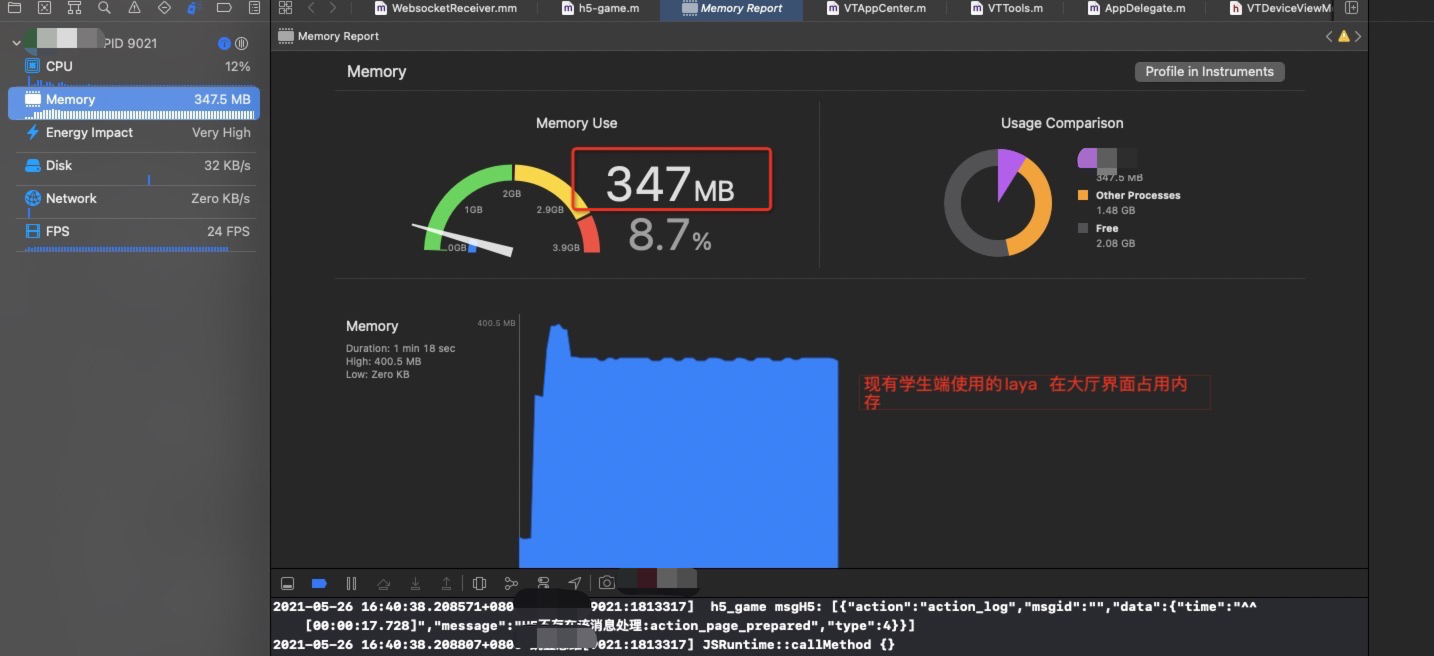
点击切换,干掉laya
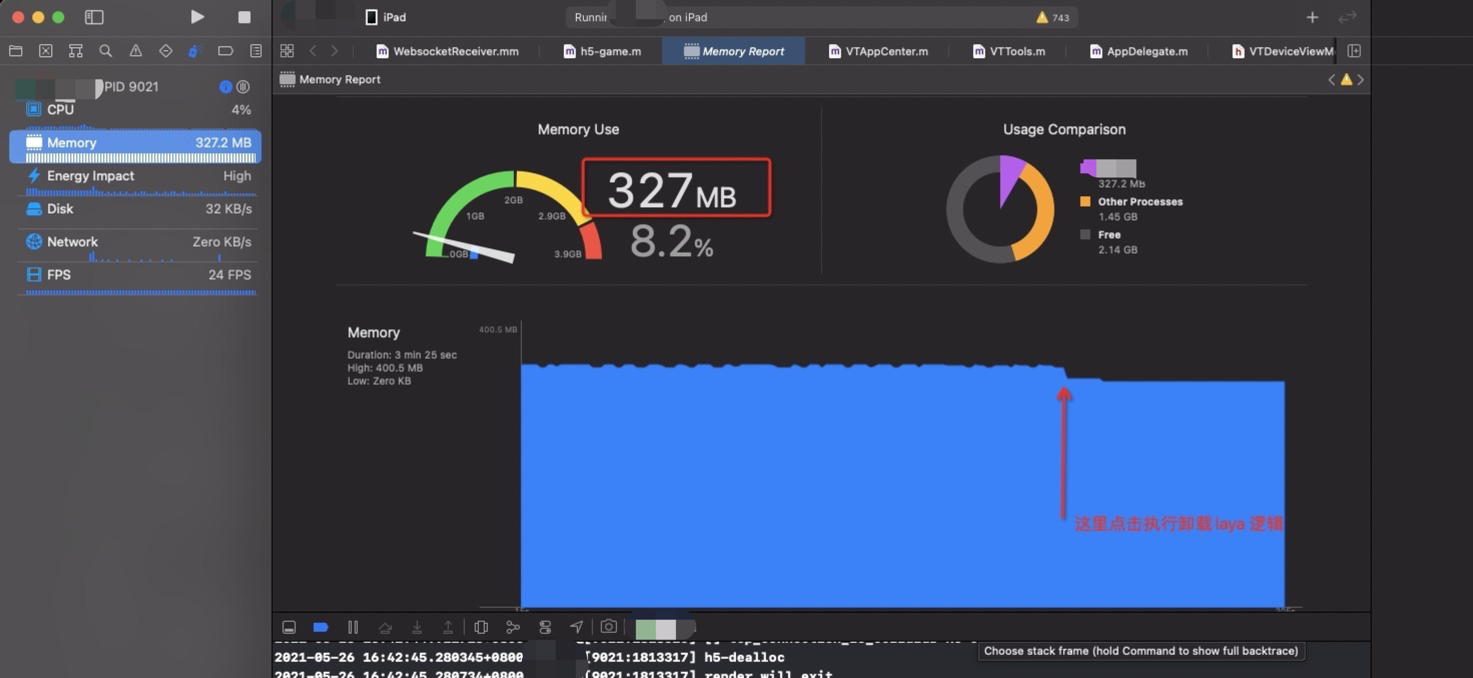
再次拉起
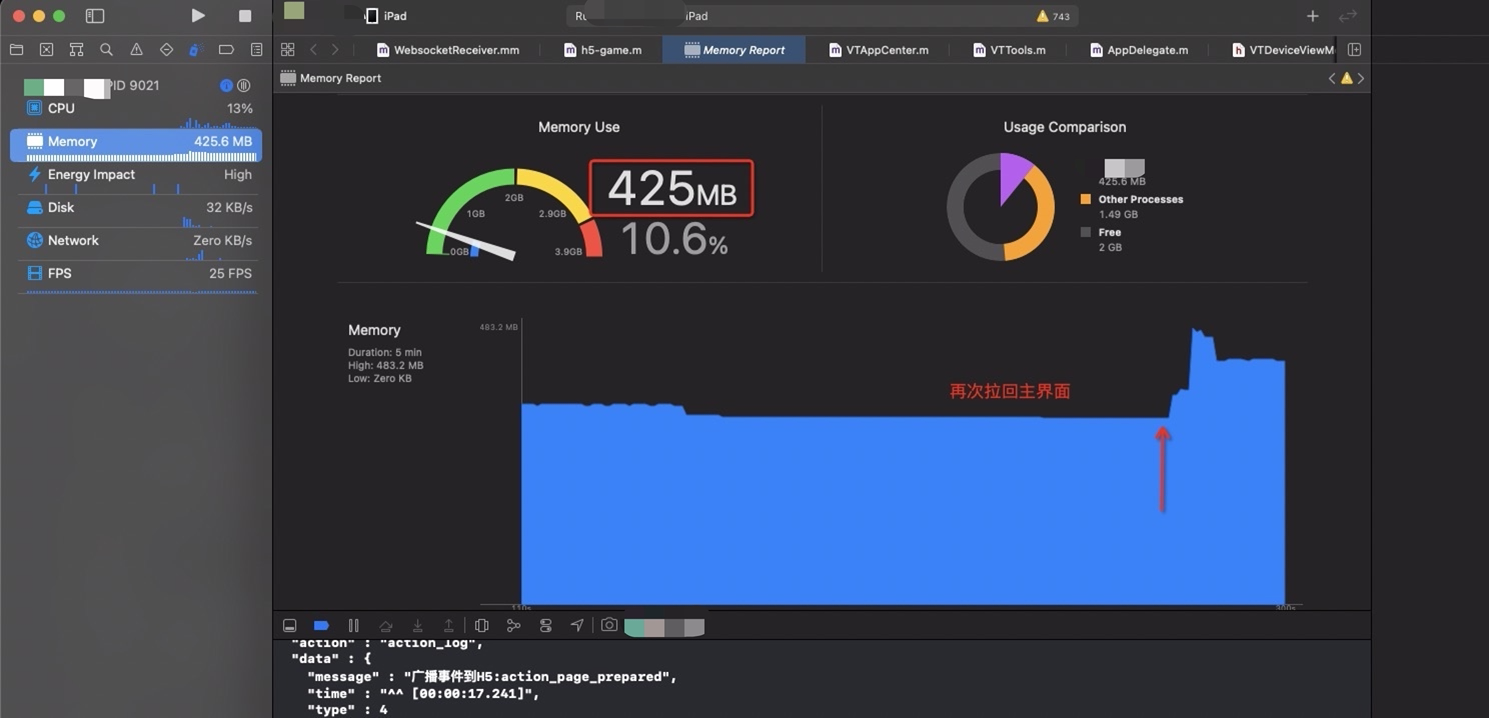
会持续增加
按照 登录→大厅→录播课→回到大厅
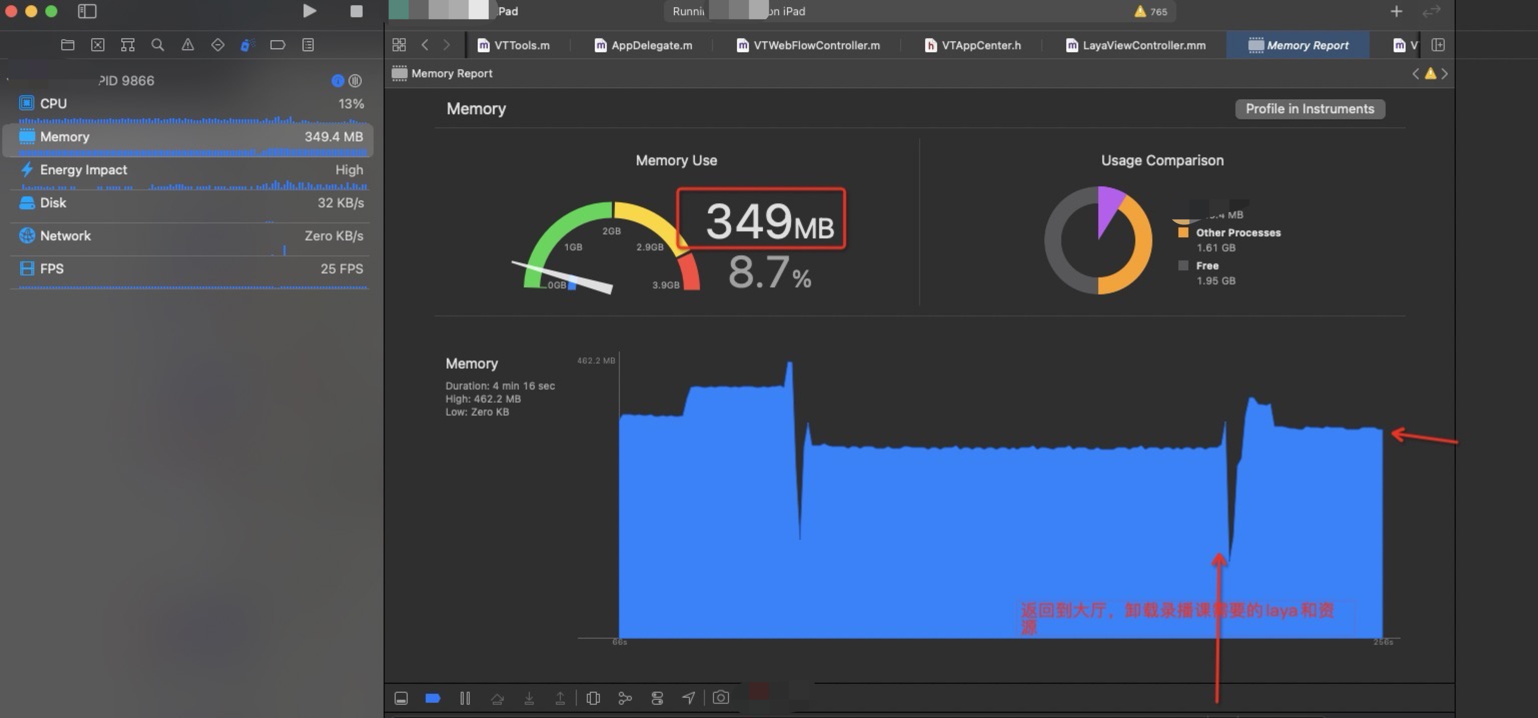
新版本二进制,移除laya 时候内存
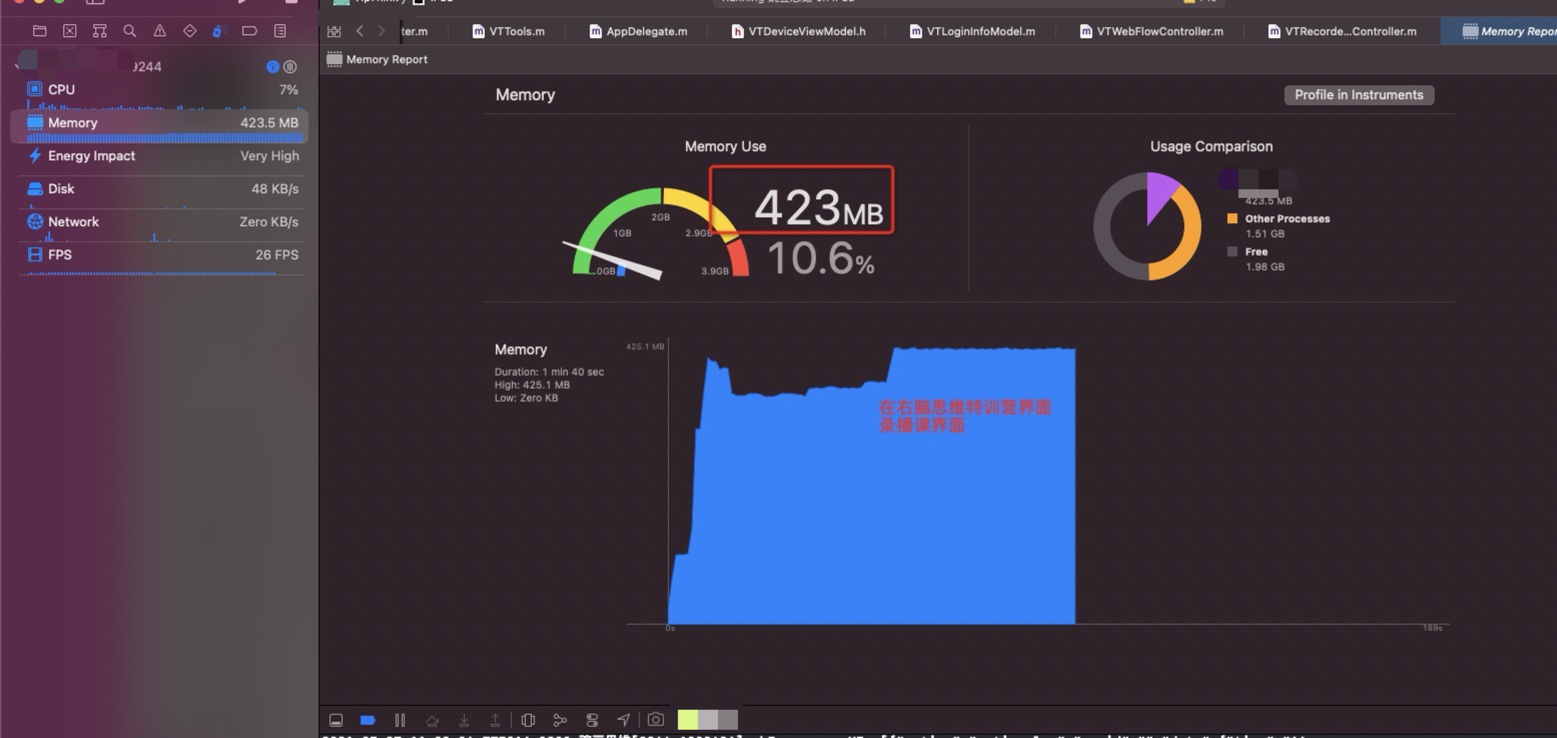
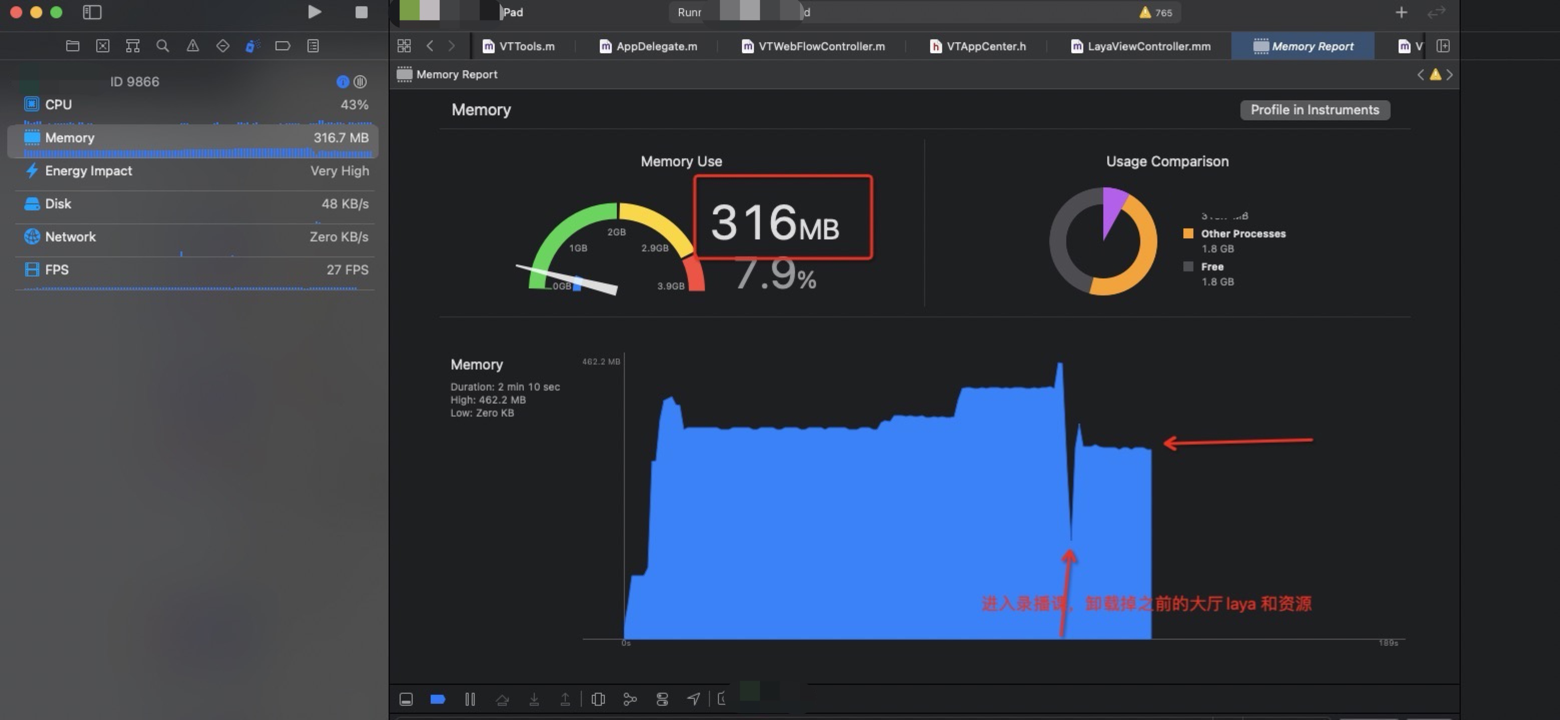
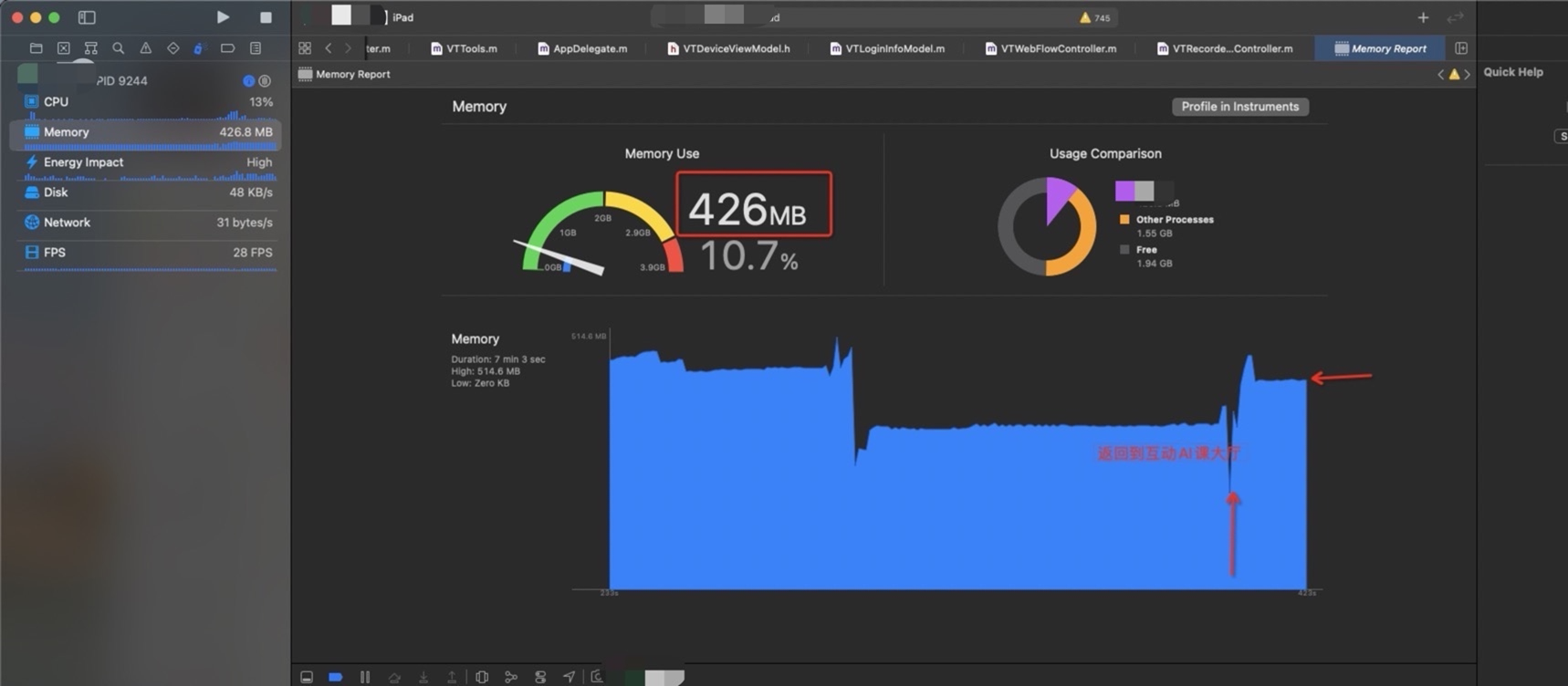
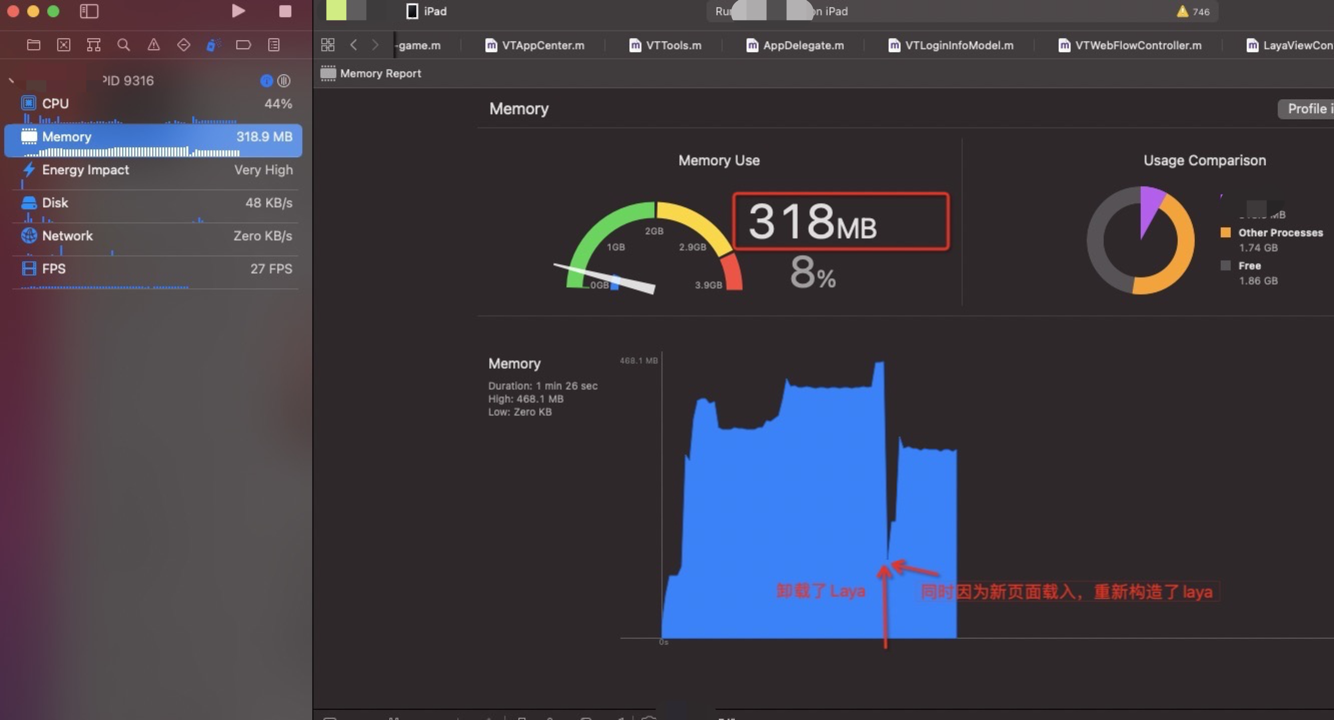
没有做修改的内存
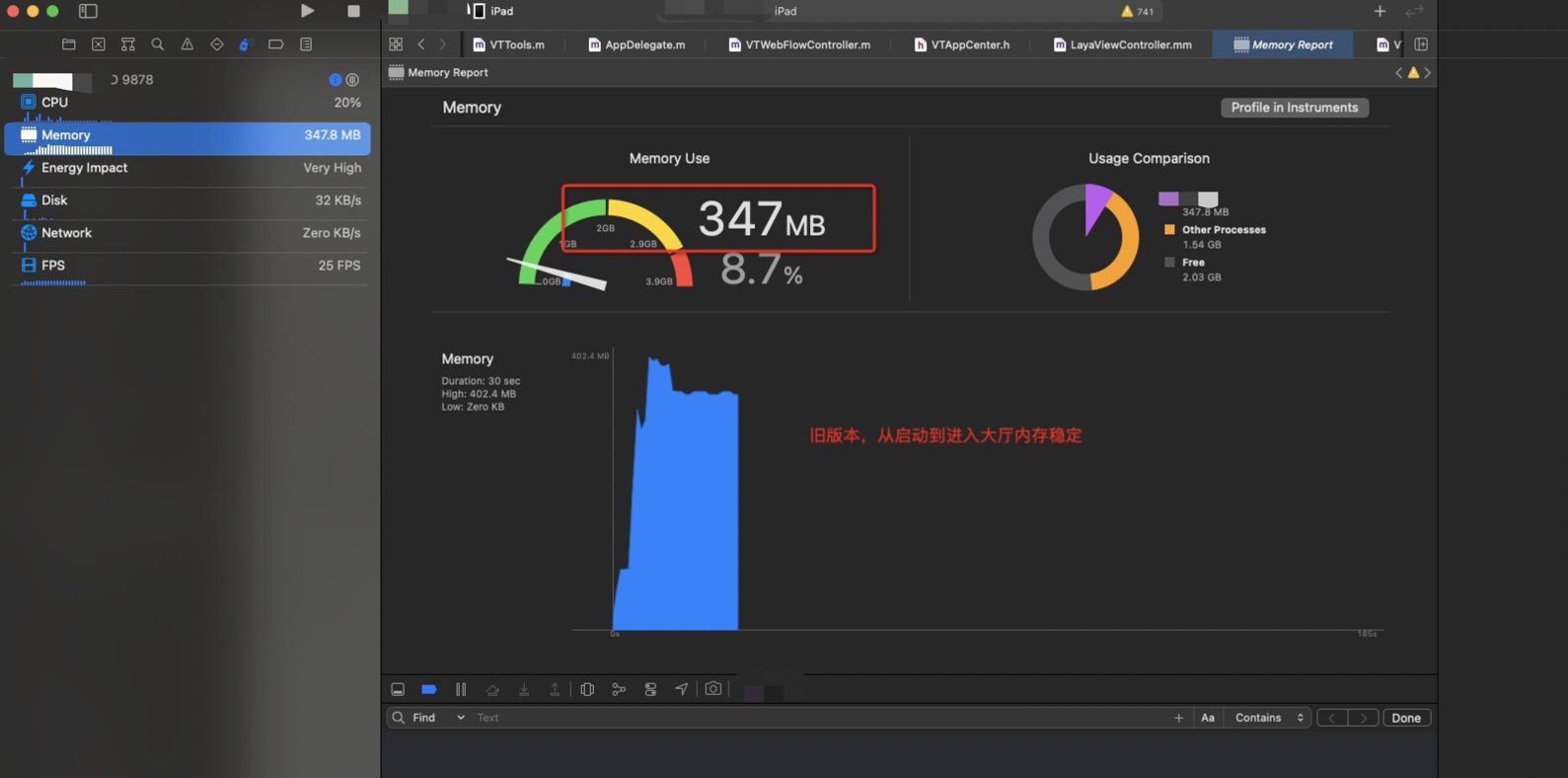
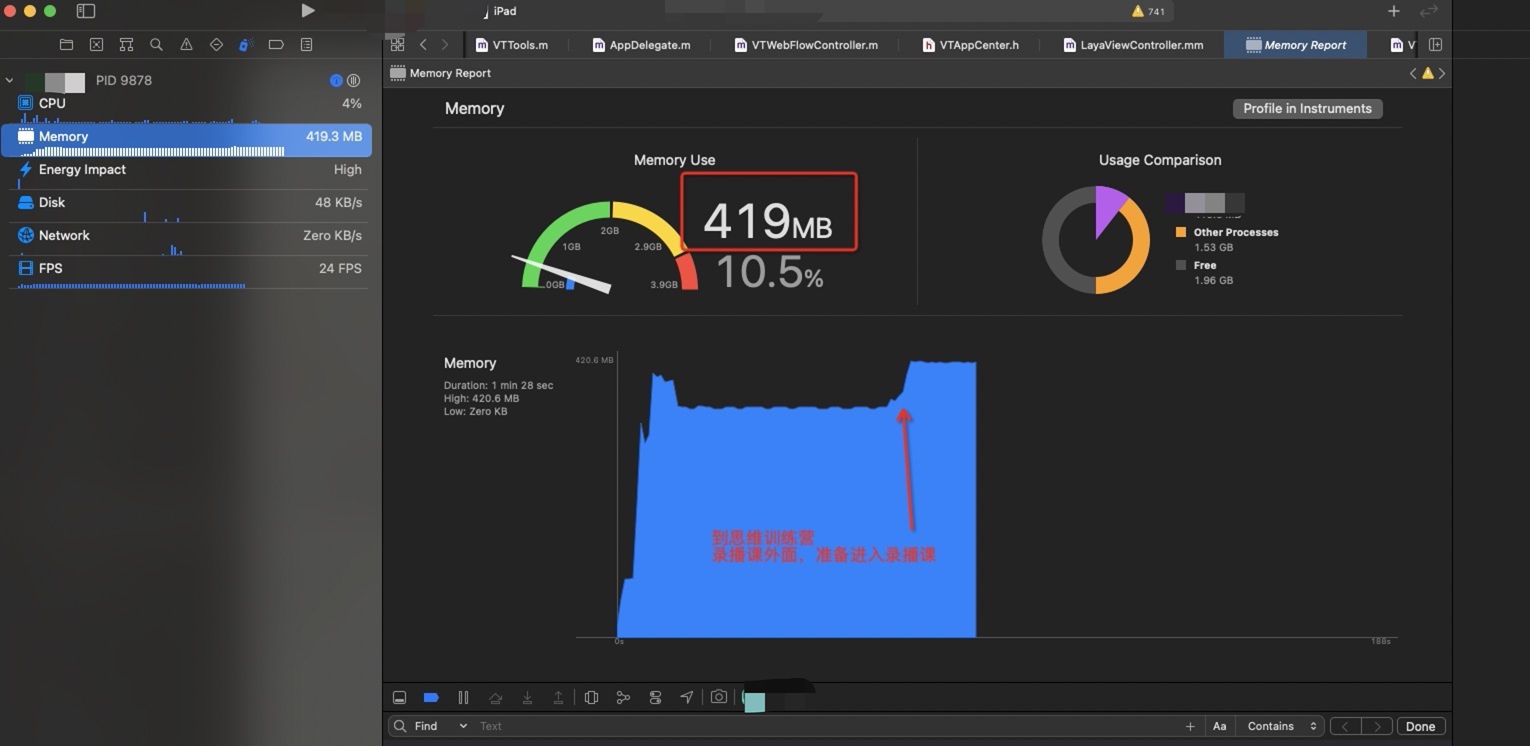
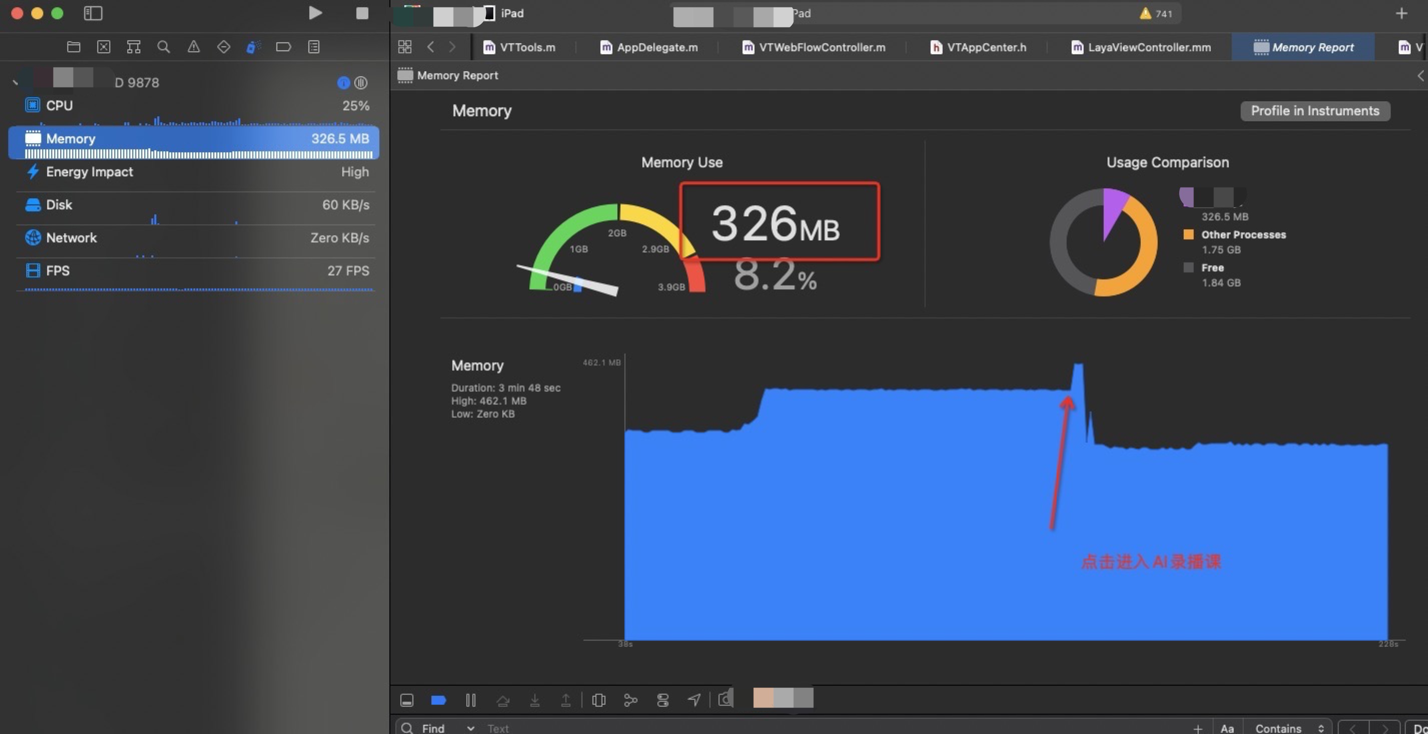
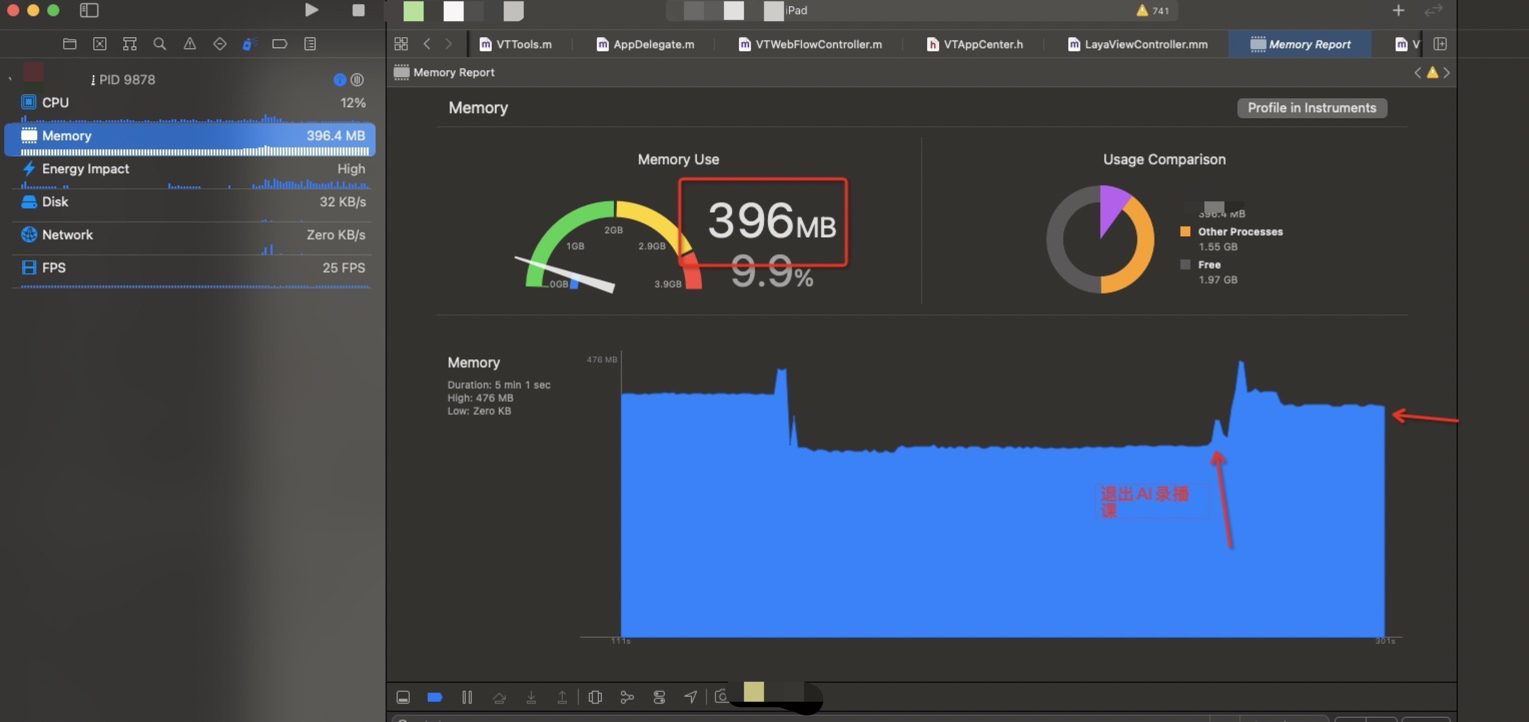
对比两种二进制,在laya 是否卸载方面内存变化结论
很明显能够看到在切换场景的时候内存有一个很深的释放,因为在释放完成第一个layacontroller之后会重新建立一个新的layaController , 这里会有一个很深的尖角,因为需要载入新的场景和资源,内存会再次上升。因为小游戏在运行时候必须的内存大小基本固定,所以会回归到正常的内存数值。
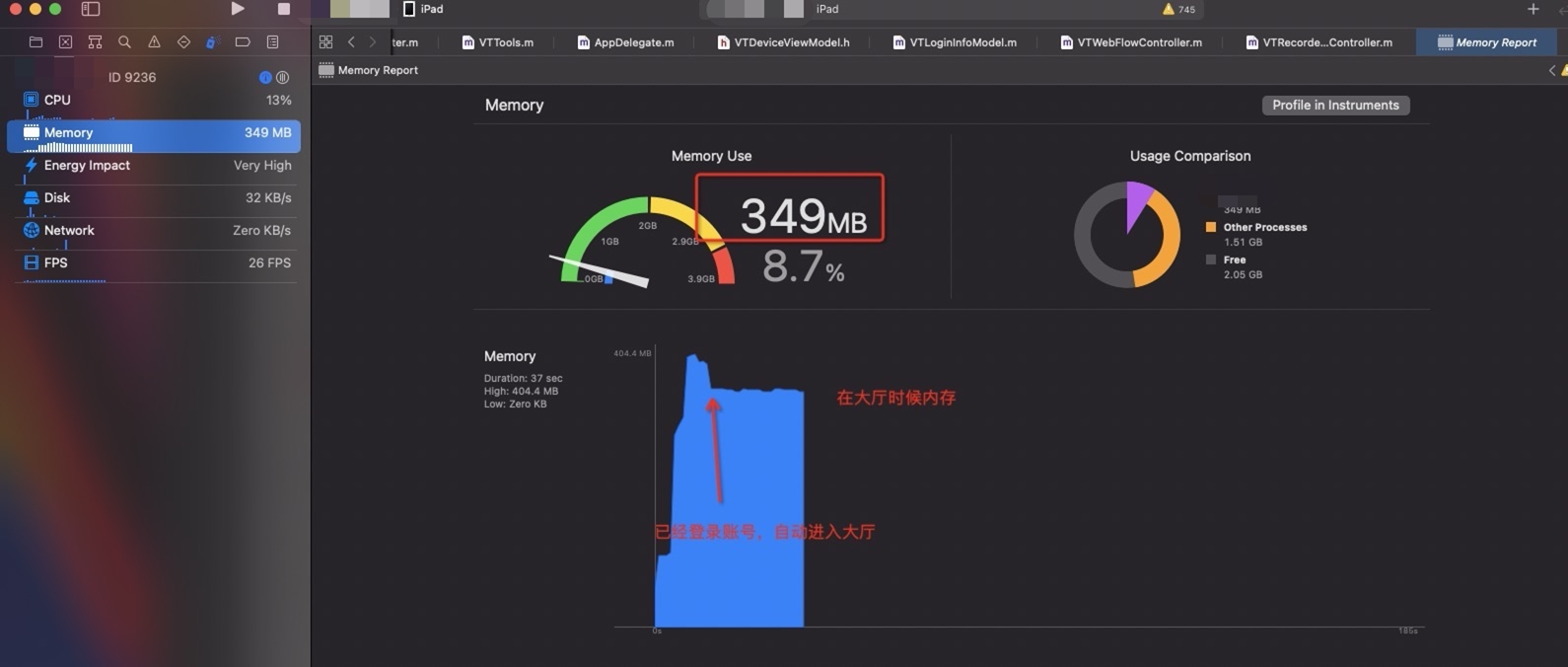
现有Laya 单利方式在内存表现方面没有太多的增加,在大厅进入到录播AI课的时候会有一定的内存上涨,在从录播AI课回到大厅的时候,一些内存没有释放掉,维持在 396M 左右, 在使用释放laya 的方式,在回到大厅时候,维持大厅刚进入时候的内存值,即 349M 左右。
有一个明显不一样的地方是,如果在新版本中大厅切换到一个空的页面,即无laya 运行时环境,iOS 内存能够从 349M 下降到 85M 左右(如下图), 但是现有的版本,内存无法下降
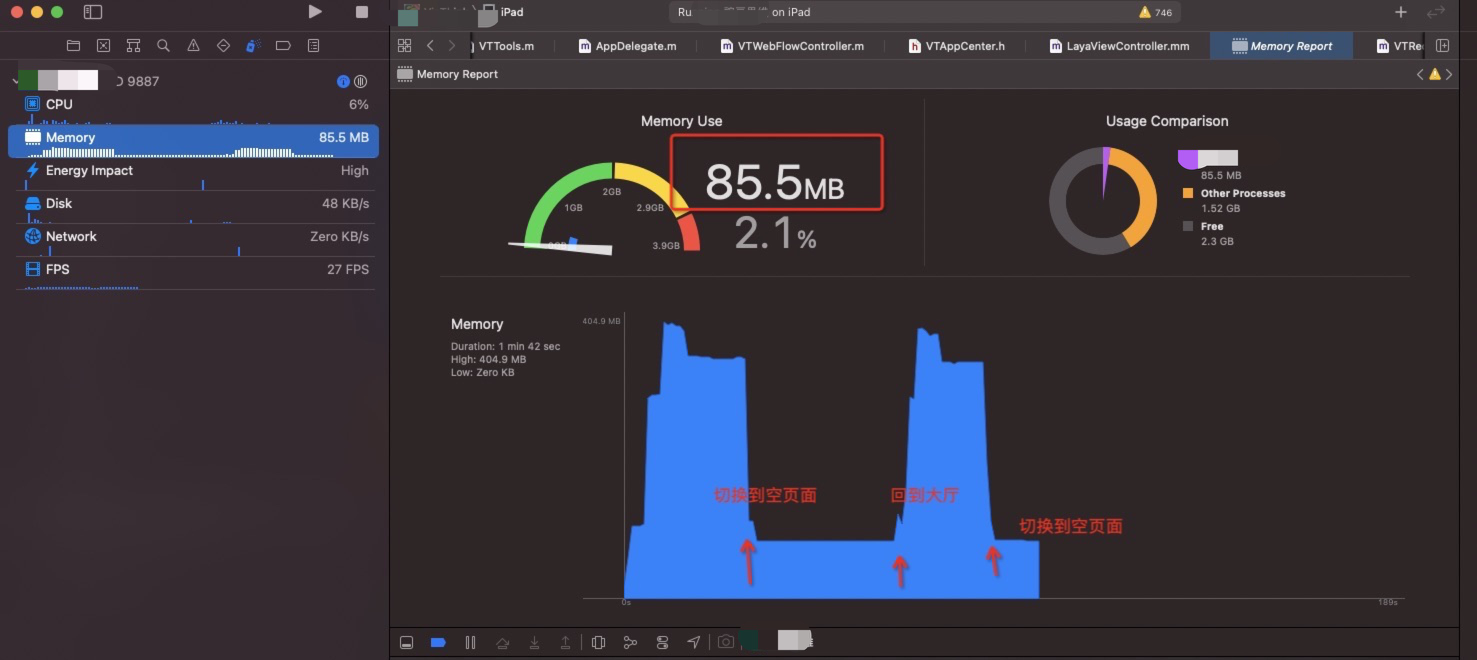
旧版本如下:
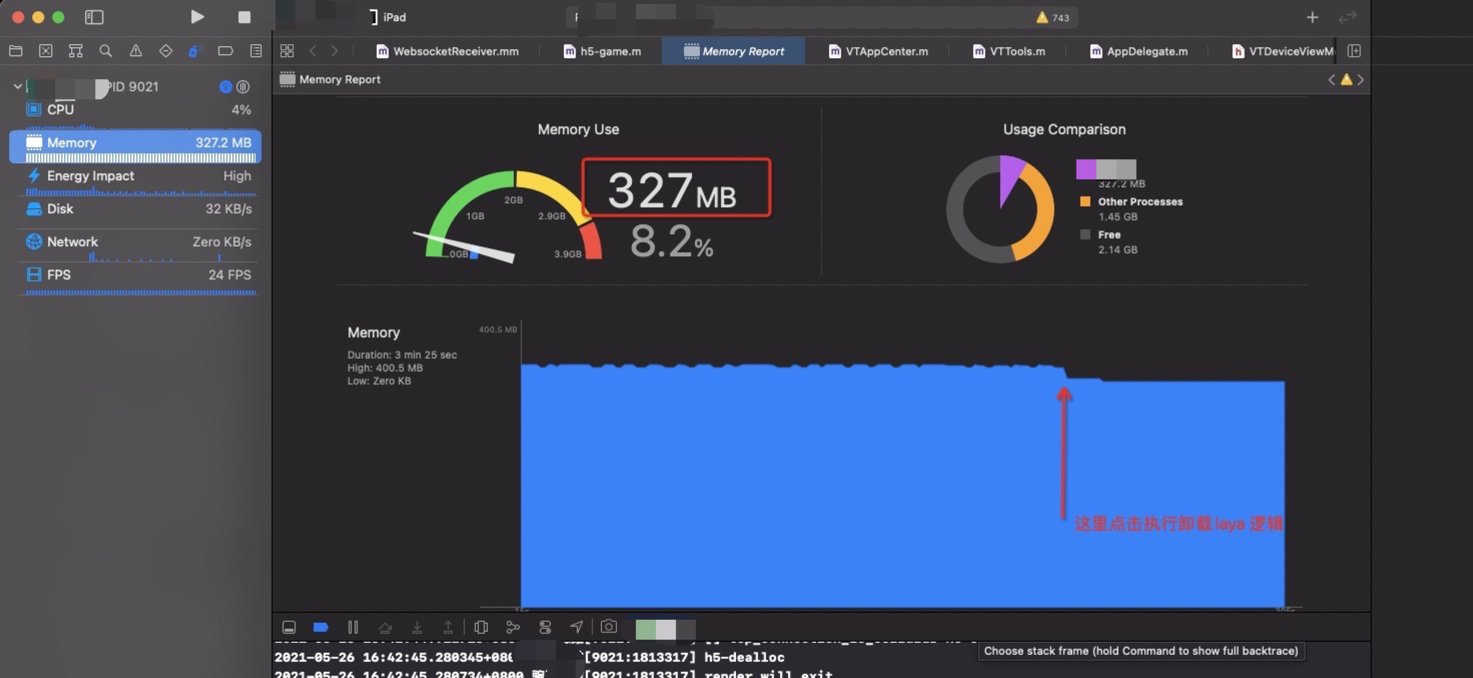
具体时机数值比较
Laya单独一个课件载入到一个新的demo 中
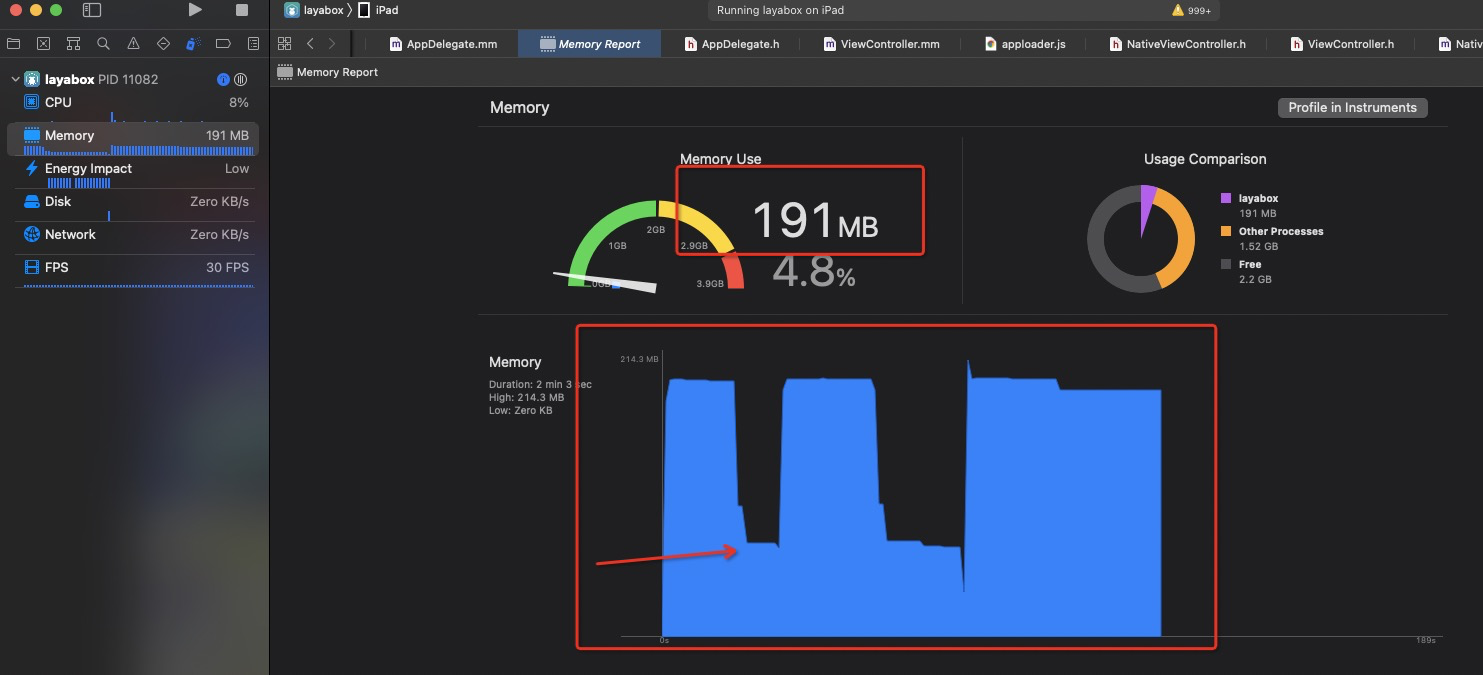
在正常运行时候 191M (这里没有声网,没有录播课中的视频,只是laya 课件), 但是卸载以后,就在 70.3M
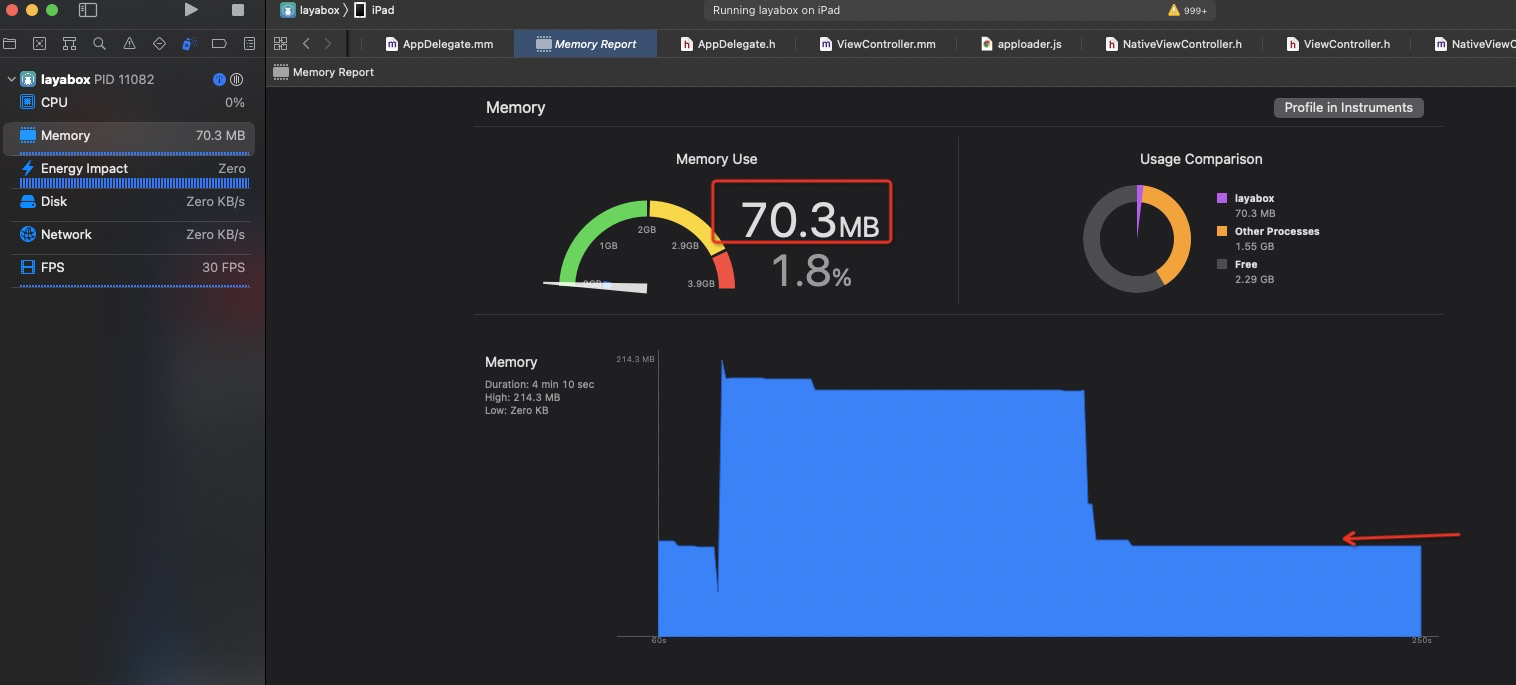
就是理论评估,本讲课件暂用内存在 121M 左右。
在学生端这里,从大厅进入—>到AI录播课→回到大厅流程 (在释放laya 对象时候进行延时处理,延时为 5秒 ,可以详细的记录内存的变化)
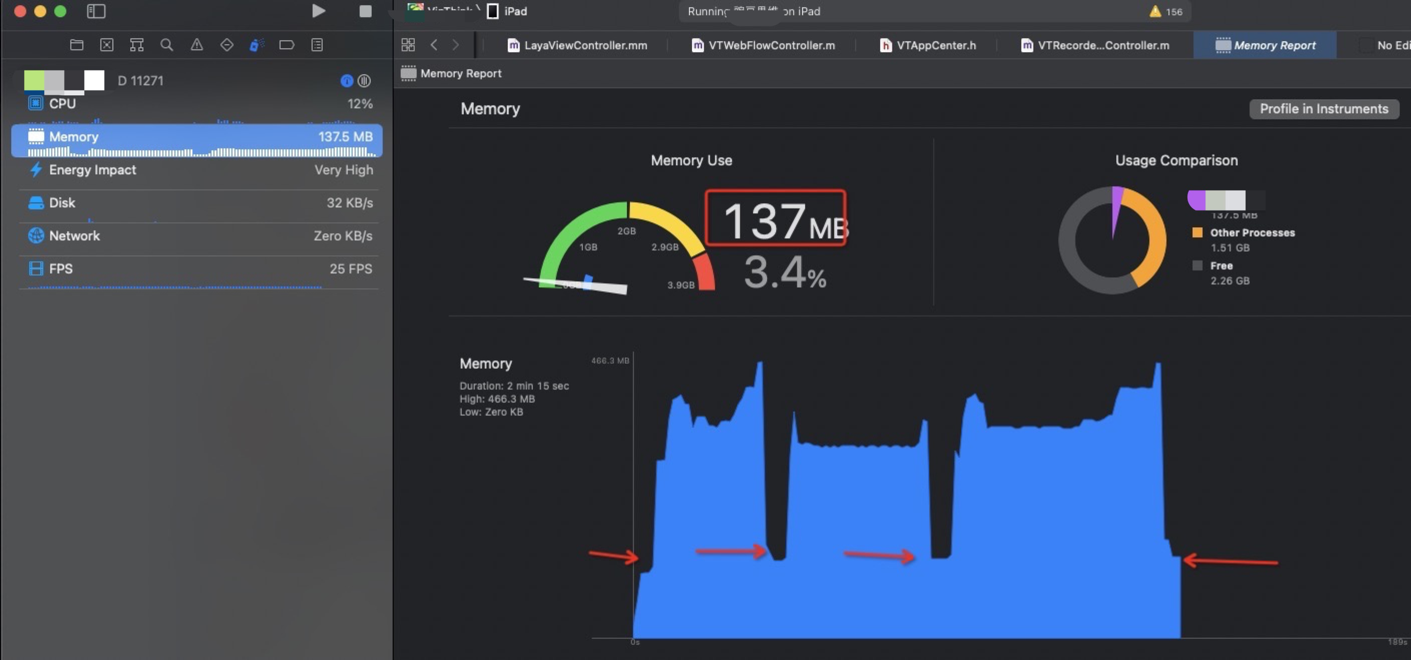
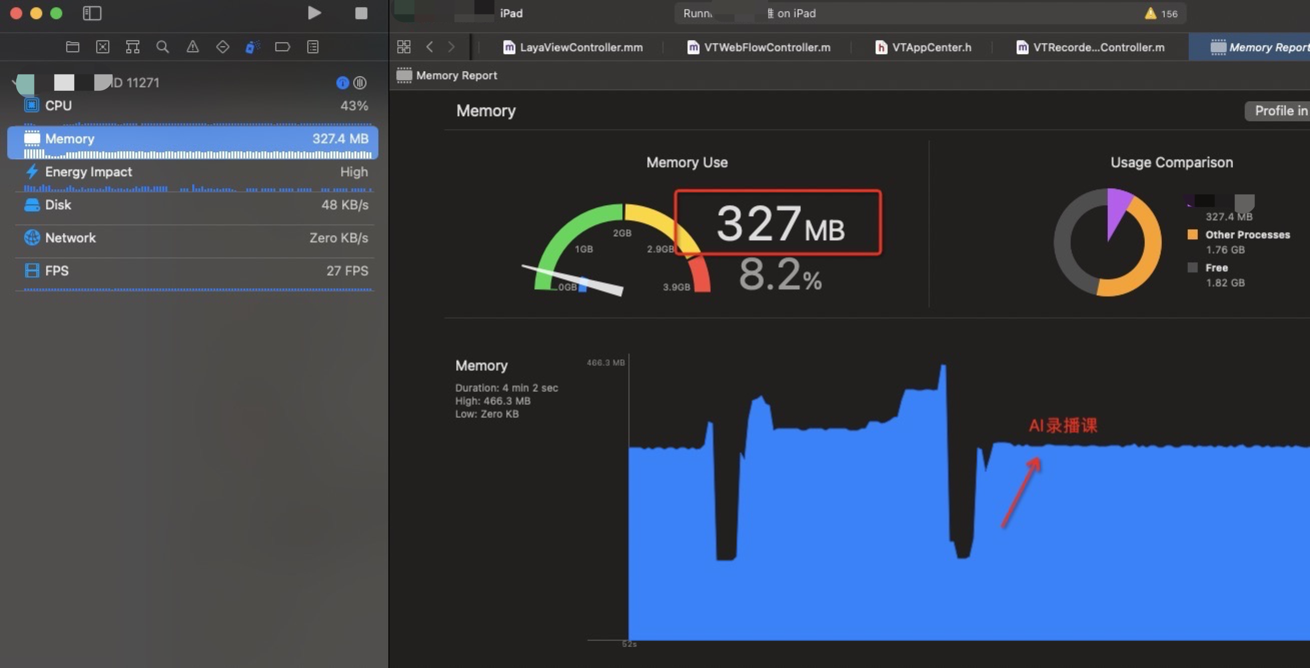
327 - 137 = 190M (相比上面单独demo 中的 121M ,应该算是合理的)
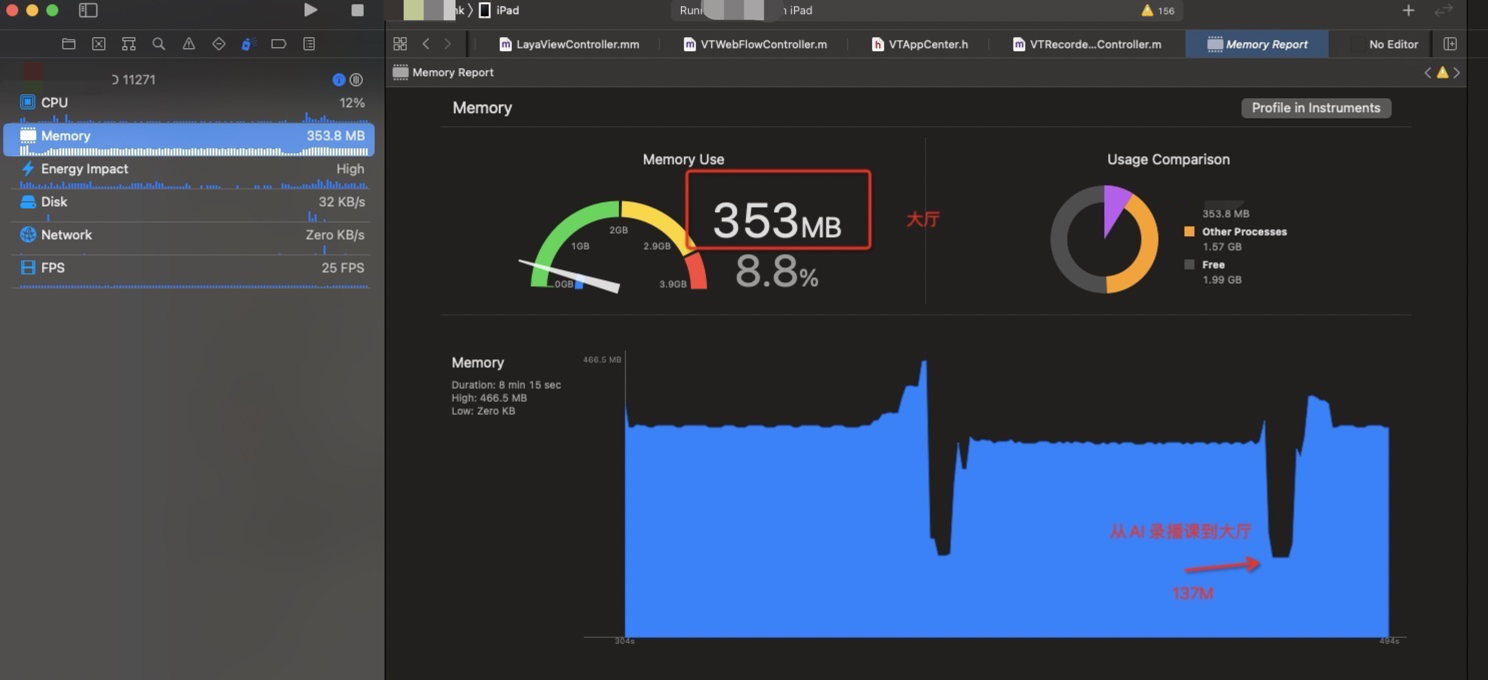
大厅课件占用内存 353 - 137 = 216 M
关于性能方面初步结论:
在同等环境下,运行时候需要的内存是一致的,但是在于卸载laya 到原生端这里,2.1.0
版本因为laya 引擎自身原因,引擎运行分配出来的内存和JavaScript context,资源内存并没有被释放。导致再次拉起Laya 工程,内存会重新分配,出现严重的内存泄漏。2.11.0 版本,修改以后是可以释放掉laya运行时内存,不会因为多次释放和重新拉起引起内存泄漏。
渲染侧:
暂时还需要低端机器和相关测试环境对比
内存比对
比如线上debug 版本,进入ai课执行空游戏,即载入空场景表现
redirect url 之后内存维持在 169M
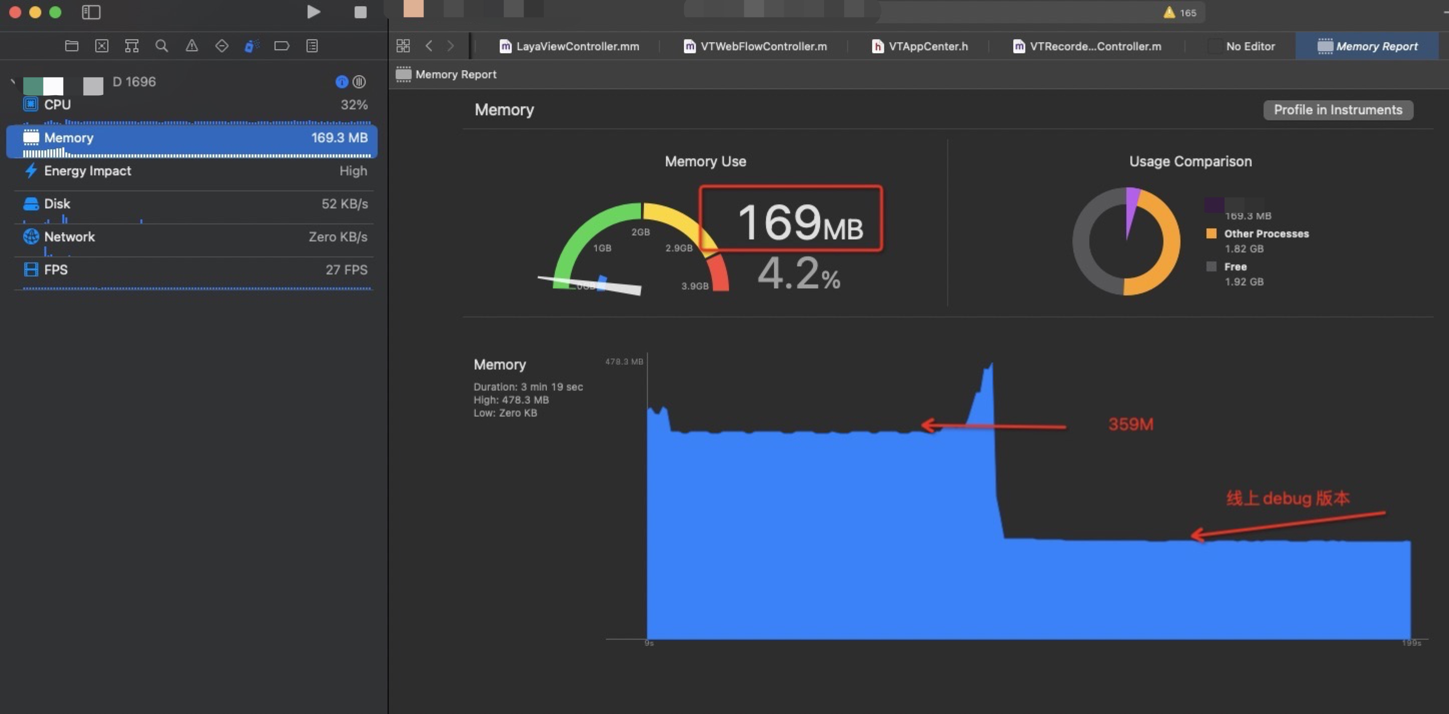
如果使用卸载Laya 方式
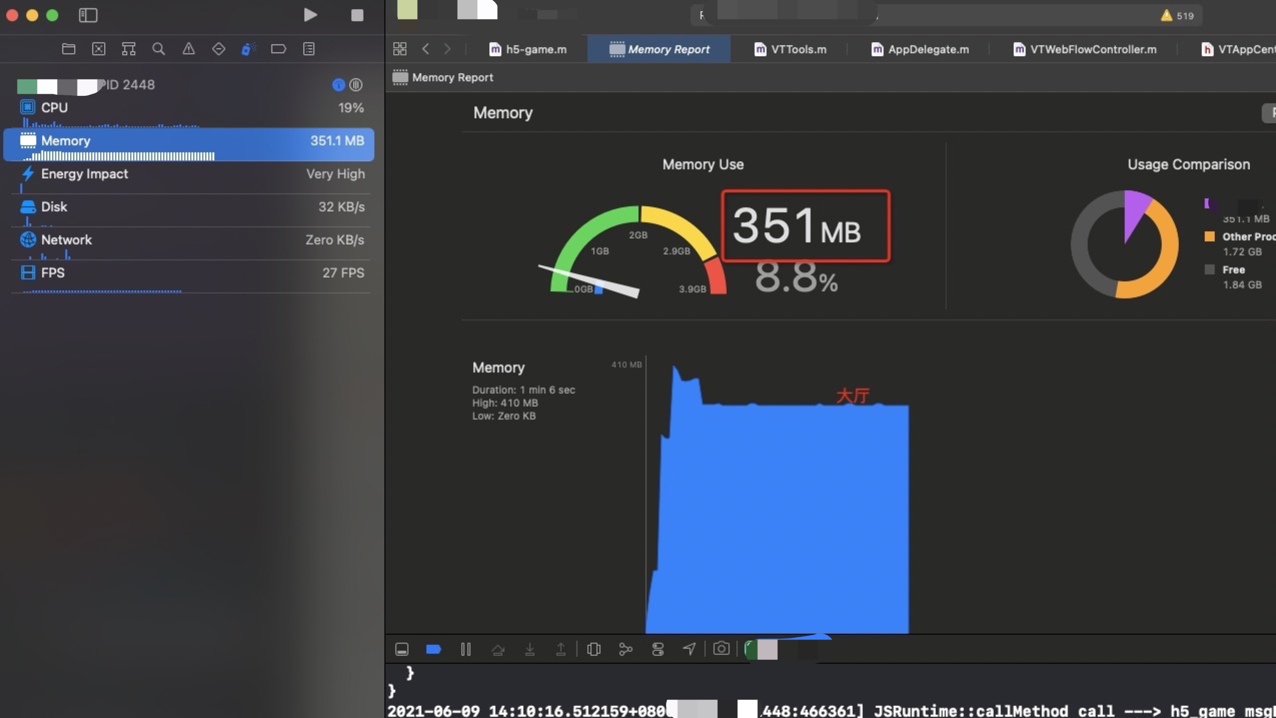
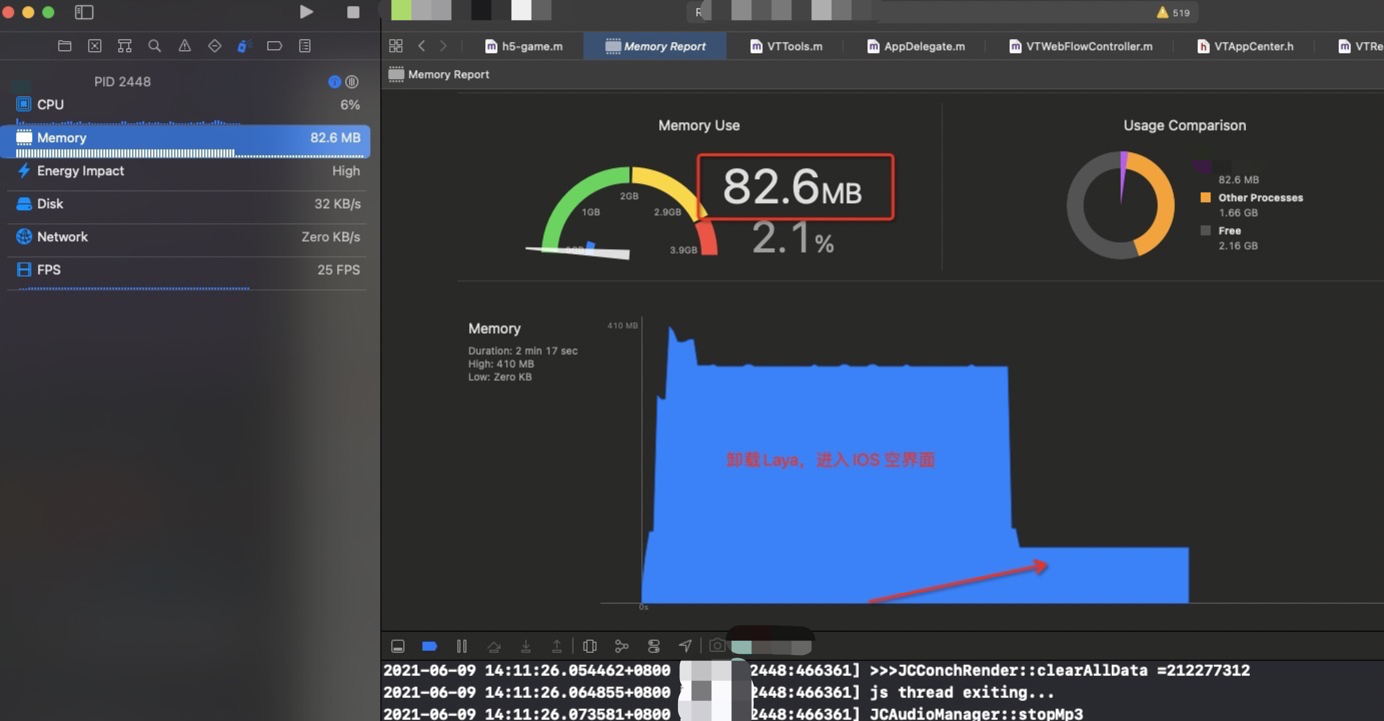
相当于如果使用修改后的引擎,在不使用Laya 的环境中 相比之前稳定在 169M 的内存, 能够减少 169 - 82.6 = 86.4M , 也就是说可以多出来 86.4M 内存提供给额外业务使用。
后续升级:
现有iOS升级可更改的内容非常少,主要修改点在于:
- iOS 之前单利方式的Laya Controller 更改为对象方式,在需要的时候载入初始化,不需要的时候可以销毁。
- 替换新版本 laya 原生二进制文件(必要)
- JavaScript 部分,修改或者替换apploader.js ,index.js 新增 webglPlus.js
新版本特性:
- 在新版本Laya 代码中使用的是 WkWebview,iOS 可以使用高版本二进制进行新项目提审。
- 支持内存释放,可以做多runtime 引擎之间切换。
- 具备扩展性,可以在现有基础上对引擎底层做特定修改。
leetcode 总结 09 反转链表
leetcode 09 反转链表
一道比较有意思的题,也觉得是链表里面需要掌握的一道题
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:
输入:head = [1,2]
输出:[2,1]
示例 3:
输入:head = []
输出:[]
提示:
链表中节点的数目范围是 [0, 5000]
-5000 <= Node.val <= 5000
进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
作者:力扣 (LeetCode)
链接:https://leetcode-cn.com/leetbook/read/linked-list/f58sg/
1 | public: |
leetcode 总结 08 大数相加
leetcode 08 大数相加
就最近遇到一个比较有特点的题,特点大数这个东西第一次听说这么搞。
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和。
提示:
num1 和num2 的长度都小于 5100
num1 和num2 都只包含数字 0-9
num1 和num2 都不包含任何前导零
你不能使用任何內建 BigInteger 库, 也不能直接将输入的字符串转换为整数形式
因为给出的大数是 字符串,考虑到需要逆序,比较容易的方式在自己了解不多的语言中认为 Python 比较好用,因为字符串逆序和字符串分割为数组会比较简单。于是就这么干了
1 | class Solution: |
leetcode 总结 01 两数之和
leetcode 总结 01 两数之和
经历了非常严重的一整年加班以后,开始想着不要继续碌碌无为了。算法这些东西,不管是需要找工作临时练手熟悉,或者是学习,总是要有的。
废话不多说。
两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 103
-109 <= nums[i] <= 109
-109 <= target <= 109
只会存在一个有效答案
1 | class Solution { |
leetcode 总结 02 只出现一次的数字
leetcode 总结 02 只出现一次的数字
只出现一次的数字
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明:
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
示例 1:
输入: [2,2,1]
输出: 1
示例 2:
输入: [4,1,2,1,2]
输出: 4
作者:力扣 (LeetCode)
链接:https://leetcode-cn.com/leetbook/read/top-interview-questions/xm0u83/
1 | // 最开始考虑是不是先要排序,然后相邻的进行比较 , 但是不需要额外空间这个要求就一定会有诡异,所以查了一下解题技巧,果然很有一套 |