Nodejs 使用Buffer
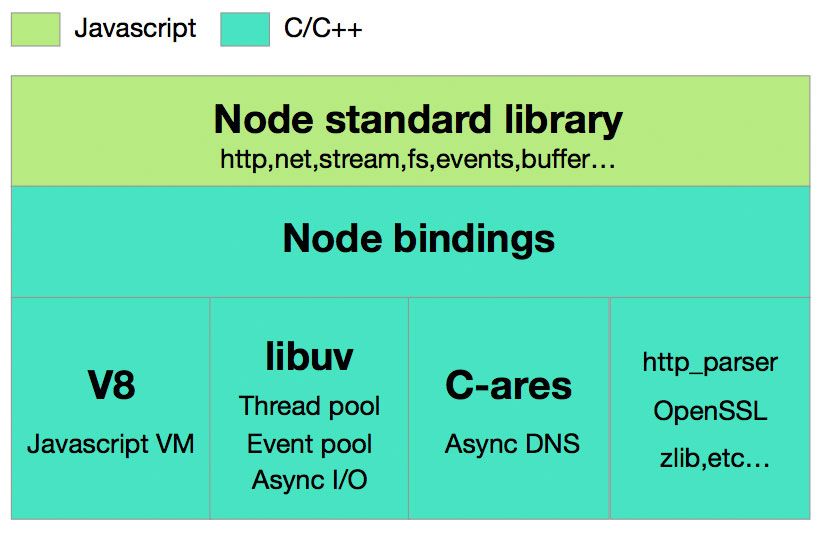
为什么需要在Nodejs 中使用 buffer ? 如上图所示,Nodejs 最外层接口是JavaScript,内部的具体执行是C++ 。由于JavaScript的灵活易用性和使用广泛性,暴露接口为JavaScript这一点对于快速开发绝对是有利的。虽然纯粹JavaScript 语言本身可以使用buffer , 但是与C++相比,对于二进制数据类型内容处理,JavaScript 表现的并不擅长。因为Nodejs 的底层是依赖于C++ , 所以为了更好的发挥各项语言之间的擅长,提升产品的性能,JavaScript 与C++ 之间的buffer 通信就是一种必然。在Nodejs中存在着重要的一个模块儿,Google V8 。依赖于V8提供的扩展API,JavaScript 可以比较容易的跟C++ 进行通信。
我们的产品在PC端使用的是Electron(基于Nodejs),在关于图形图像和文件处理方面也会有使用场景。
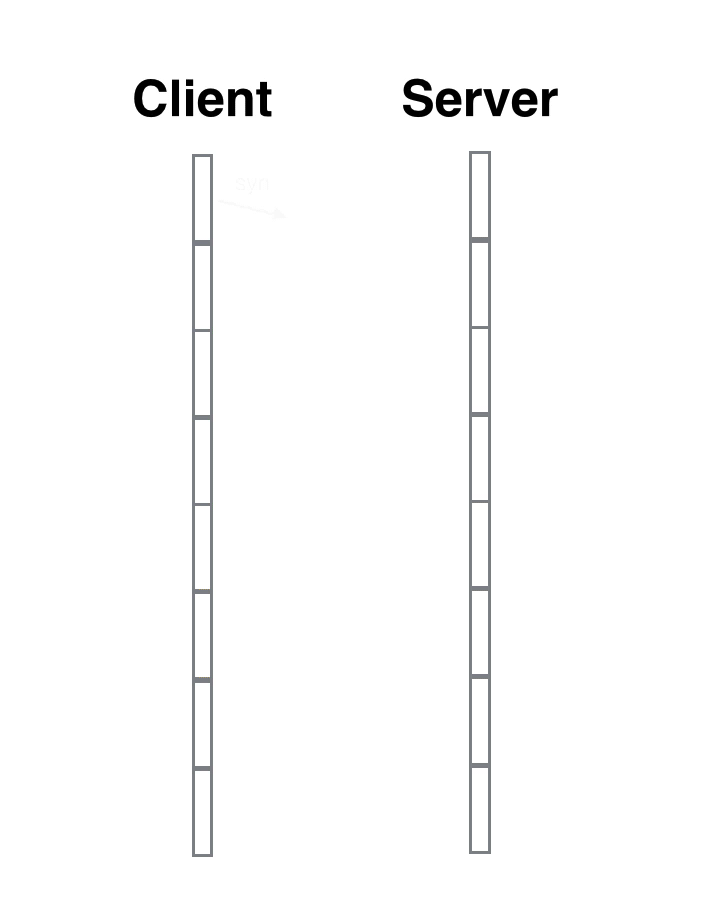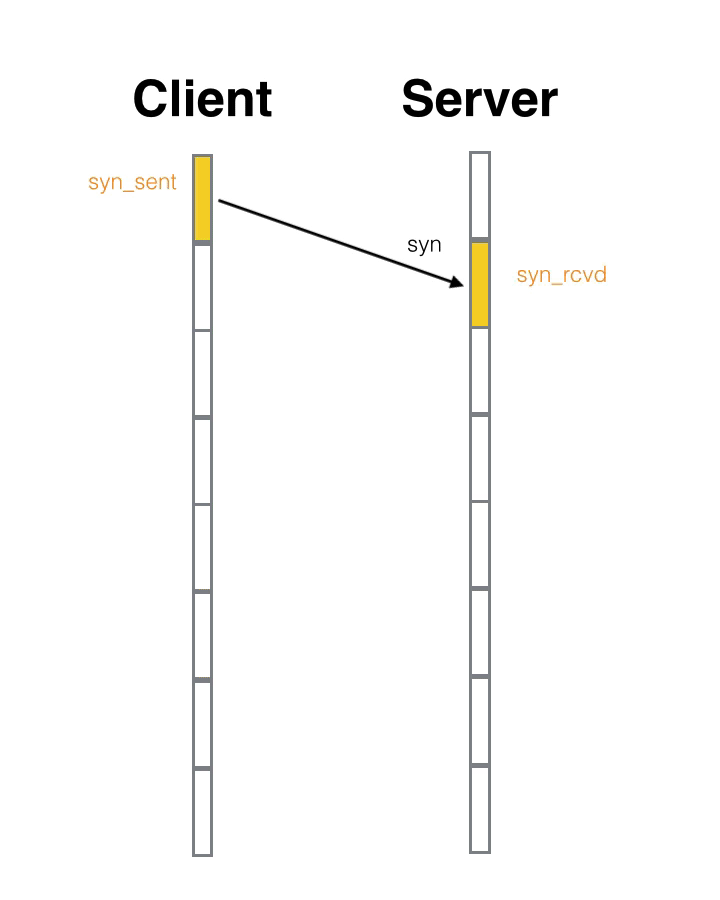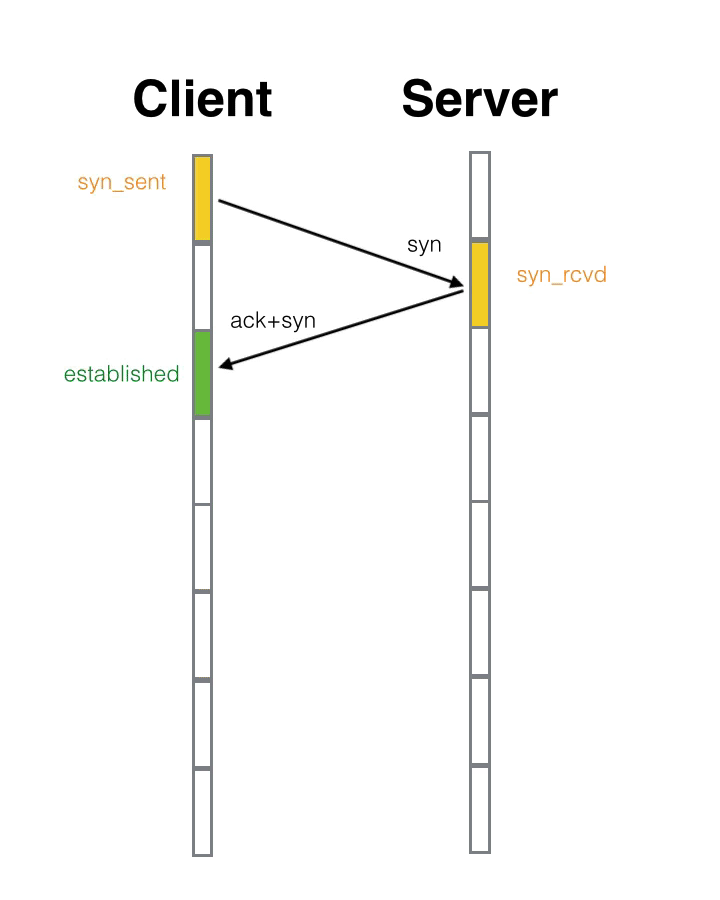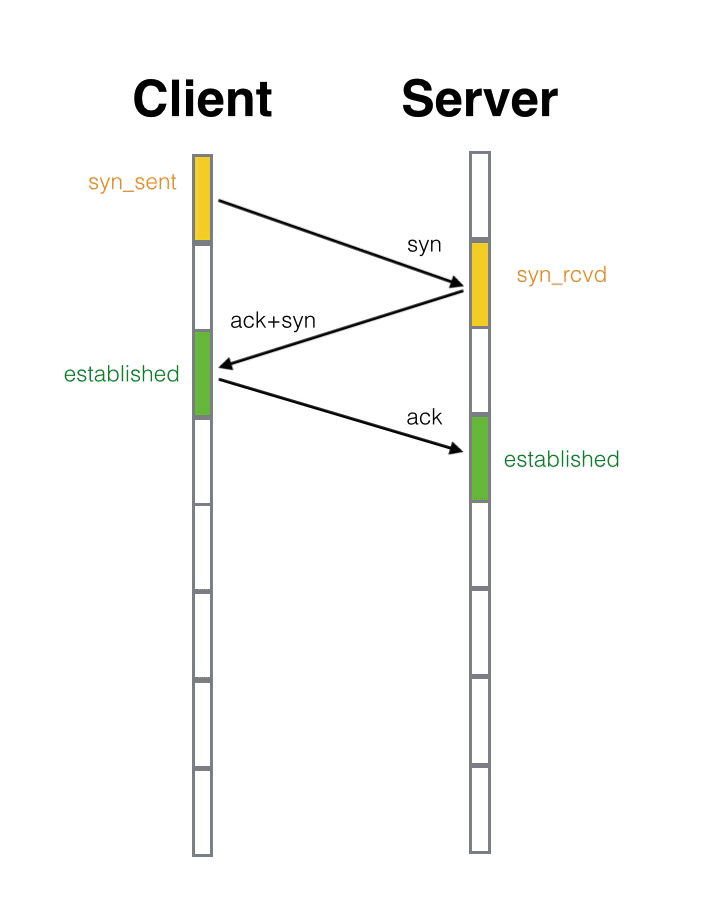
如何使用,会有什么样的问题 ? 根据NodeJs 的架构图我们也能发现一些问题,我们需要处理不同语言之间的信息交互。所以单单从语言层面来讲,通用的做法,两个语言之间进行通信,需要在不同的语言中各自分配一份内存用于存放数据交换的内容。对于buffer 数据而言,在长度不固定前提下,两个语言都要重新分配和释放连续内存再加上内容拷贝就会显得效率不会很高。但是Nodejs 中有V8。
因为Nodejs 有V8 的存在,JavaScript 中间需要分配的交换数据可以经过V8分配和持有的内存用来存储,但是V8 持有的内存又跟平常C++ 分配的内存一样。V8 Data 持有的储单元是可通过 V8 的 C++ API 访问的,但这些又不是普通的 C++ 变量,这些存储单元只能够通过受限的方式访问。
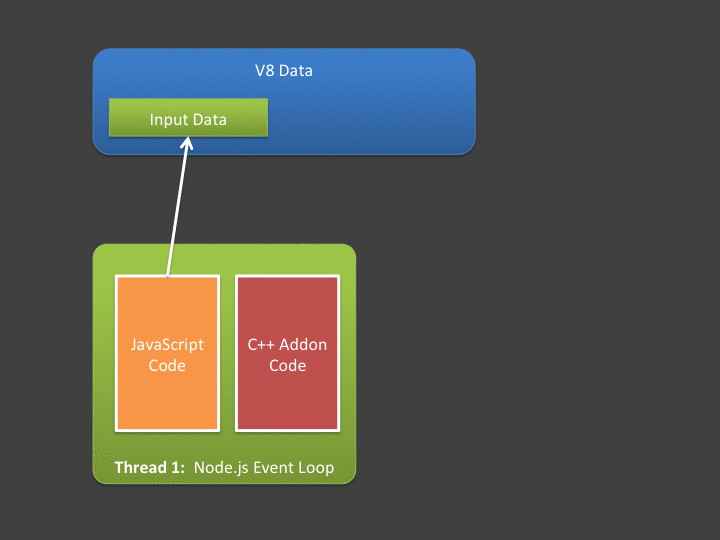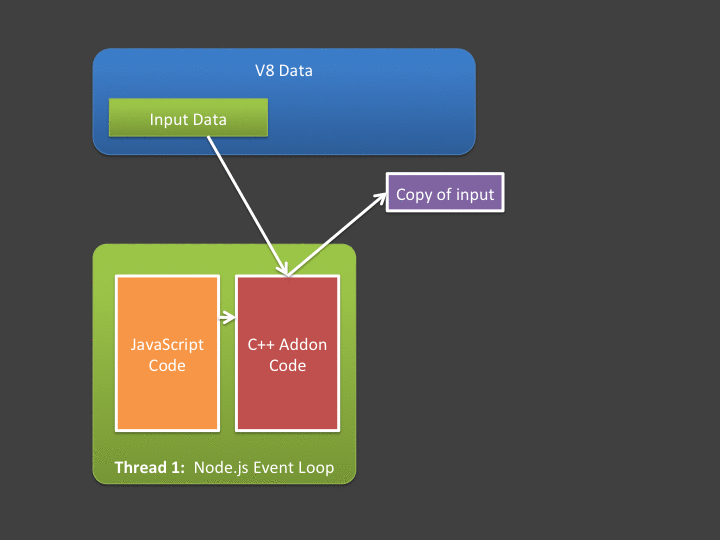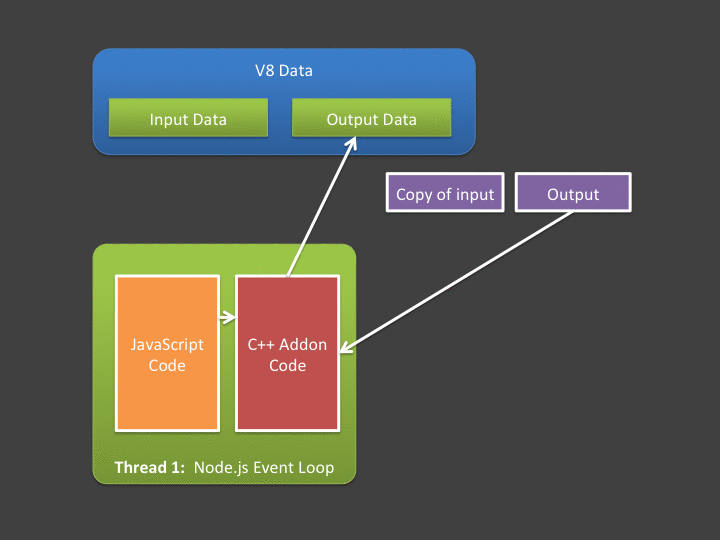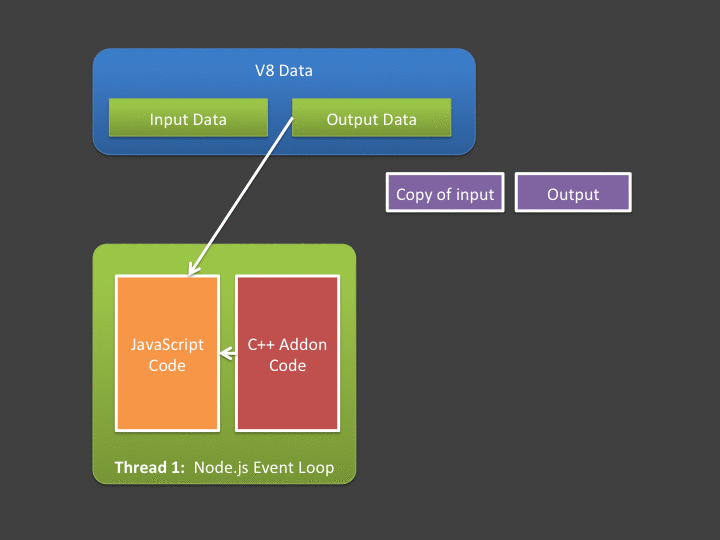
如果把V8存储单元作为“桥” ,那么数据拷贝的交互模式就会如下。
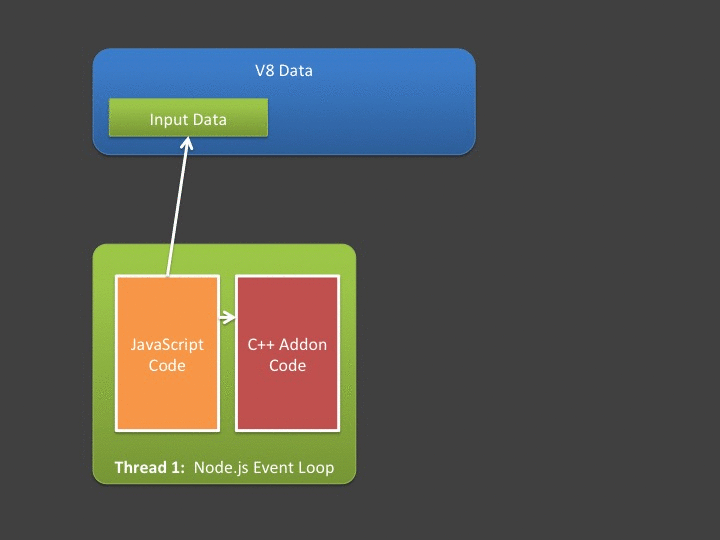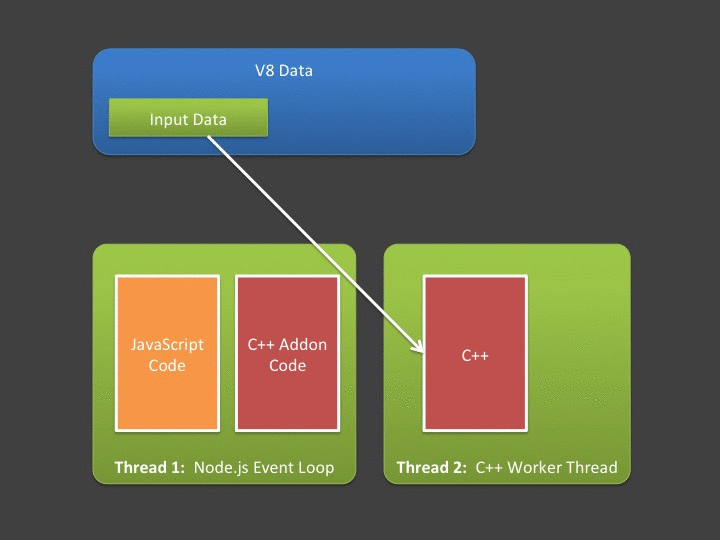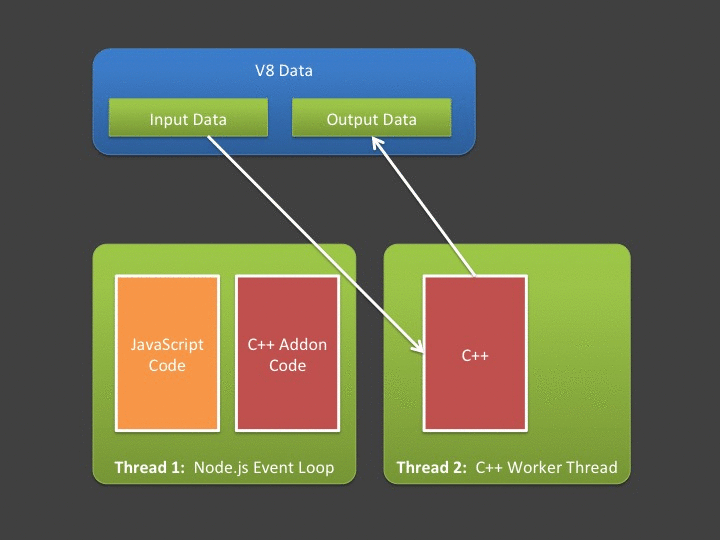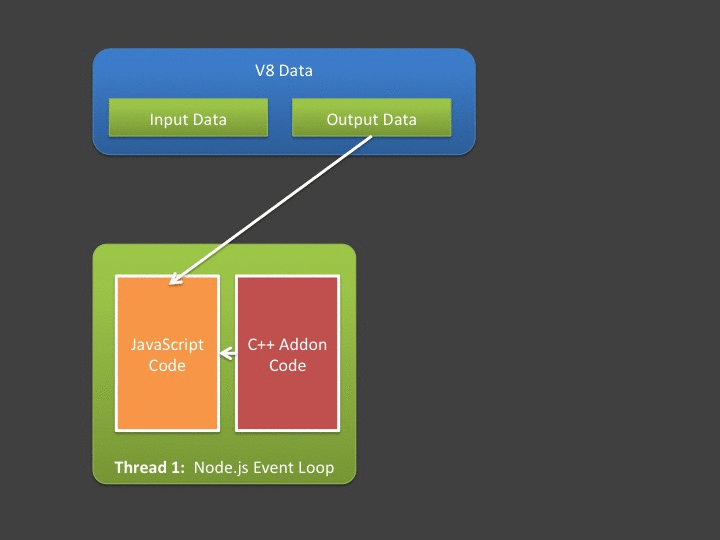
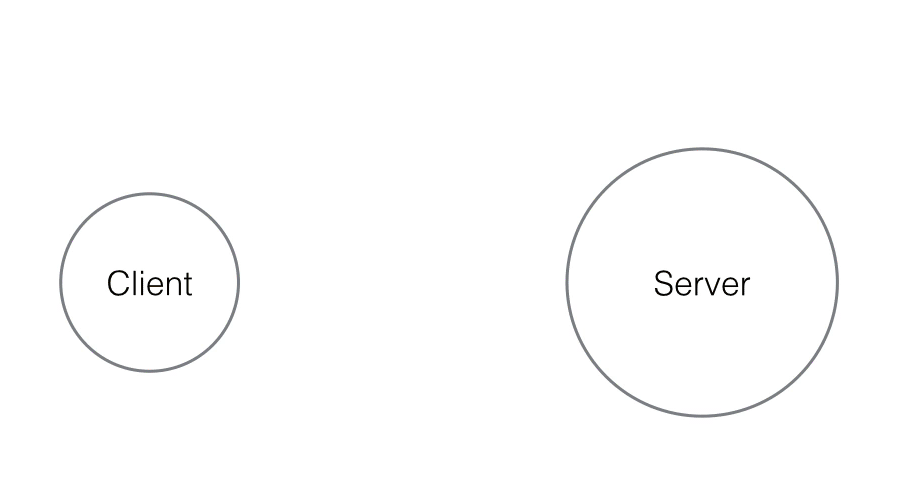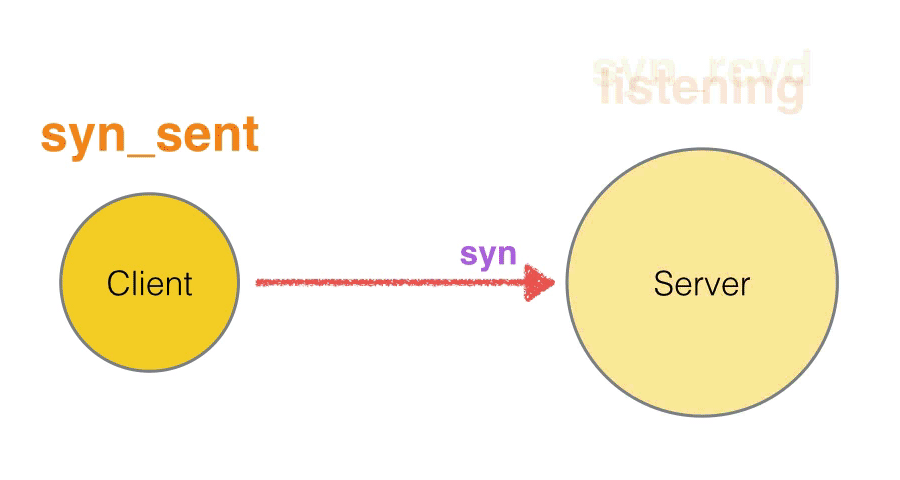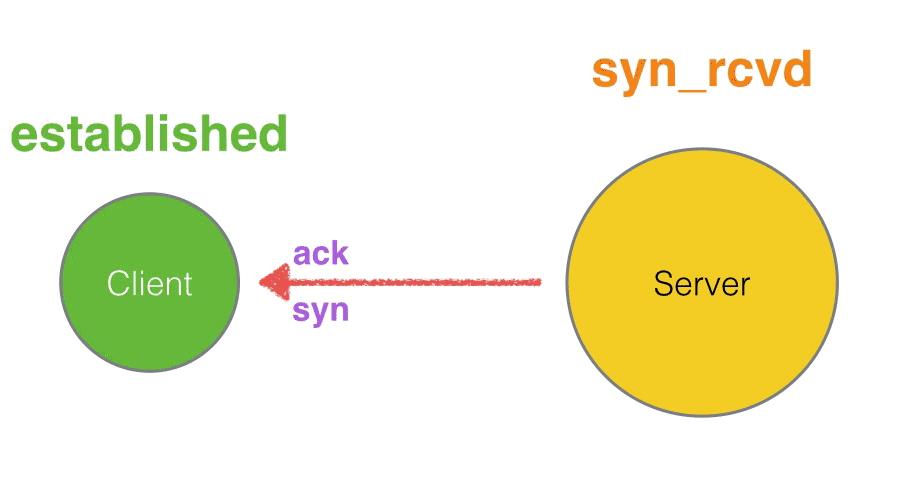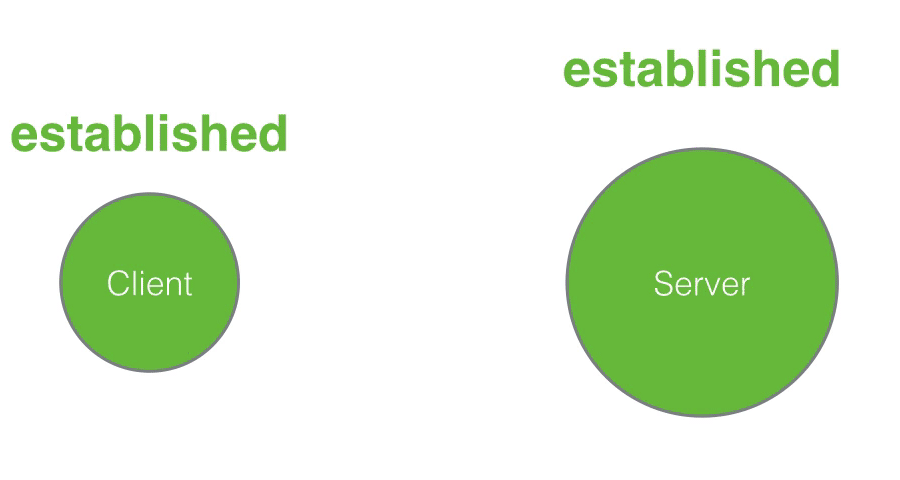
JavaScript 向C++ 发送数据的流程就是,JavaScript 准备需要发送的buffer 数据,让V8存储单元进行存储,然后通过Nodejs 提供的交互API,调用C++,先在C++ 层进行数据拷贝。这样就完成了数据的单向发送。同步方式阻塞方式直接返回数据的流程就是,在C++ 中获取到处理后的Output 数据,通过V8 持有存储单元,执行Nodejs 提供的API , 可以把数据交给JavaScript。
这样的做法似乎没什么问题,但是如果在处理大量的交互数据时候,从V8侧拷贝交换数据再给到C++ 就会需要一定的性能损失。还存在另外一个问题,就是既然使用Nodejs,依赖于C++,目的就是不能阻塞JavaScript 单线程。异步交互就会显得比较重要,在Nodejs 中,如果需要使用异步操作,那么Libuv是另外一个绕不过去的重点。
具体的执行步骤如下。
如果去掉内容拷贝,C++ 和 JavaScript 能指向并且能够直接使用V8 存储单元的数据,就是比较理想的状况。
Nodejs 对于这类问题的处理提供了一个比较合适的组件,Buffer。
用法 参考 Nodejs官方文档
JavaScript 侧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 const buf = Buffer.alloc(5 );console .log(buf);const buf4 = Buffer.from([1 , 2 , 3 ]);const buf = Buffer.from('hello world' , 'utf8' );console .log(buf.toString('hex' ));
C++ 侧
正如上面官网内容,没有丝毫的跟下层C++ 交互的内容。
为了方便理解和使用,这里提供一个Demo 方便于参考。
1 2 3 4 5 6 7 8 9 10 console .log("---------------->>>>>>>>=========" );var bufSource = Buffer.from("Hello C++ Addon!!!" );console .log("bufSource is : " + bufSource);var buffer = global .logBridge.getNewBuffer(bufSource);console .log("Direct return buffer is : " + buffer);console .log("----------------<<<<<<<<<=========" );
对于V8操作,这里需要先补充以下知识点
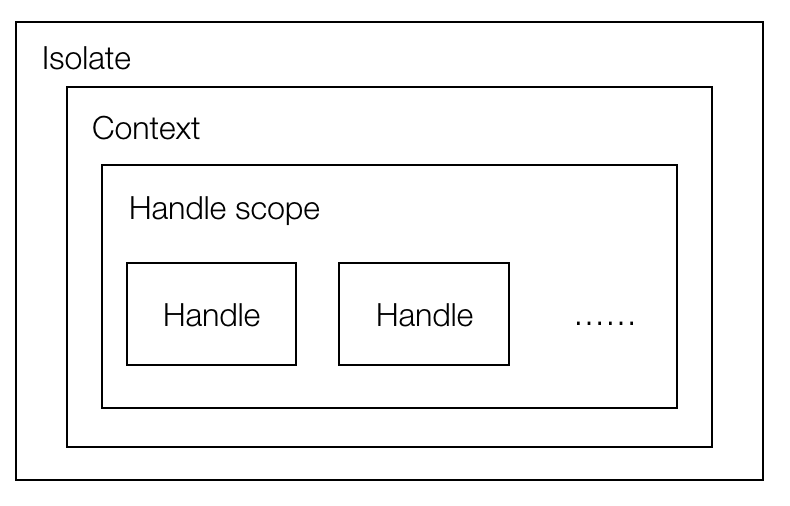
Isolate是一个独立的V8实例,也可以说一个独立虚拟机,其中可以包含一个或多个线程,但同一时间,只有一个线程是执行状态。
Context代表一个执行上下文(执行环境),它使得可以在一个 V8 实例中运行相互隔离且无关的 JavaScript 代码. 你必须为你将要执行的 JavaScript 代码显式的指定一个 context。Context支持嵌套。
Handle是一个指向堆内存的指针,在V8中JavaScript的值和对象也都存放在堆中,Handle提供了一个JS对象在堆内存中的地址的引用。有人会有疑问我们直接操作JS变量指针不可以嘛?由于V8的GC策略,可能会对堆中的JS变量移动其内存位置,Handle的出现可以跟踪相应变量的地址。
Handle Scope是一个Handle的容器,为了解决一个个释放handle过于繁琐,将一些handle接入handle scope中,方便统一管理(释放等)。
具体接受和处理代码如下
主动传递和接收
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 Nan::SetPrototypeMethod(tpl, "getNewBuffer" , getNewBuffer); void MyBuffer::getNewBuffer (const Nan::FunctionCallbackInfo<v8::Value> &info) Isolate *isolate = info.GetIsolate(); v8::HandleScope scope (isolate) ; v8::Local<v8::Object> infoObj = v8::Local<v8::Object>::Cast(info[0 ]); unsigned char *buffer = (unsigned char *)node::Buffer::Data(infoObj); size_t size = node::Buffer::Length(infoObj); for (int i = 0 ; i < size; i++) { if (i > size / 2 ) { buffer[i] += 1 ; } } info.GetReturnValue().Set(Nan::CopyBuffer((char *)buffer, size).ToLocalChecked()); }
单向从JavaScript 到 C++ , 经过V8 Buffer 再回调回JavaScript , 整个一圈就可以走完。如果发起方一直是JavaScript ,那么这个流程无疑是最直观能理解到的,但是还会存在其他的情况。 事件的发起方是C++ , 而且是多线程处理,需要把相关数据交给JavaScript,而且是多次异步回调。
补充提醒,JavaScript 只有单线程,而C++ 可以有多线程。
C++ 主动异步多线程发送,JavaScript 被动接收
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void MyBuffer::setCallback (const Nan::FunctionCallbackInfo<v8::Value> &info) v8::Local<v8::Context> context = info.GetIsolate()->GetCurrentContext(); Isolate *isolate = info.GetIsolate(); Nan::HandleScope mscope; v8::HandleScope scope (isolate) ; Local<Value> arg = info[0 ]; if (!arg->IsFunction()) { return ; } v8::Local<v8::Function> func = v8::Local<v8::Function>::Cast(info[0 ]); MyBuffer::getInstance()->callback.Reset(func); uv_async_init(uv_default_loop(), &MyBuffer::getInstance()->m_callback_async, async_on_callback); MTimer *t = new MTimer(); t->setInterval([&]() { MyBuffer::getInstance()->m_counter++; cout << "time is : " << MyBuffer::getInstance()->m_counter << endl ; string dataStr = "TimerCallBack count is " + to_string(MyBuffer::getInstance()->m_counter) + " hello " ; MyCallbackData *m_data = new MyCallbackData(); m_data->data = new char [strlen (dataStr.c_str()) + 1 ]; strncpy (m_data->data, dataStr.c_str(), strlen (dataStr.c_str())); m_data->data[strlen (dataStr.c_str())] = '\0' ; m_data->size = strlen (dataStr.c_str()); MyBuffer::getInstance()->m_BufferData_l.enqueue(m_data); uv_async_send(&MyBuffer::getInstance()->m_callback_async); }, 20 ); }
Libuv 回调,真正执行回调JavaScript 部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 void async_on_callback (uv_async_t *handle) v8::Isolate *isolate = v8::Isolate::GetCurrent(); v8::HandleScope scope (isolate) ; MyCallbackData *m_bufferData; while (MyBuffer::getInstance()->m_BufferData_l.try_dequeue(m_bufferData)) { v8::Local<v8::Object> buferObj = Nan::CopyBuffer(m_bufferData->data, m_bufferData->size).ToLocalChecked(); delete [](m_bufferData->data); delete (m_bufferData); m_bufferData = nullptr ; const unsigned argc = 1 ; v8::Local<v8::Value> argv[argc] = {buferObj}; try { v8::Local<v8::Function> m_call = v8::Local<v8::Function>::New(isolate, MyBuffer::getInstance()->callback); Nan::Call(m_call, isolate->GetCurrentContext()->Global(), argc, argv); } catch (const std ::exception &e) { std ::cerr << e.what() << '\n' ; } } }
Libuv 总结
1 2 3 4 uv_async_init(); uv_async_send(); void async_on_callback (uv_async_t *handle)
通过libuv 就可以异步从 C++ 子线程发起回调启动, libuv 通过内部loop 在合适时机交给主线程 ,然后执行具体 回调函数。
附赠代码demo NodejsC++AddonBuffer